Funzione | Descrizione
+--- | ---
+Correzione immediata | Supporta correzione immediata e ricerca degli errori di grammatica del documento con un solo clic
+Traduzione cinese-inglese immediata | Traduzione cinese-inglese immediata con un solo clic
+Spiegazione del codice immediata | Visualizzazione del codice, spiegazione del codice, generazione del codice, annotazione del codice con un solo clic
+[Scorciatoie personalizzate](https://www.bilibili.com/video/BV14s4y1E7jN) | Supporta scorciatoie personalizzate
+Design modularizzato | Supporta potenti [plugin di funzioni](https://github.com/binary-husky/chatgpt_academic/tree/master/crazy_functions) personalizzati, i plugin supportano l'[aggiornamento in tempo reale](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)
+[Auto-profiling del programma](https://www.bilibili.com/video/BV1cj411A7VW) | [Plugin di funzioni] [Comprensione immediata](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) del codice sorgente di questo progetto
+[Analisi del programma](https://www.bilibili.com/video/BV1cj411A7VW) | [Plugin di funzioni] Un clic può analizzare l'albero di altri progetti Python/C/C++/Java/Lua/...
+Lettura del documento, [traduzione](https://www.bilibili.com/video/BV1KT411x7Wn) del documento | [Plugin di funzioni] La lettura immediata dell'intero documento latex/pdf di un documento e la generazione di un riassunto
+Traduzione completa di un documento Latex, [correzione immediata](https://www.bilibili.com/video/BV1FT411H7c5/) | [Plugin di funzioni] Una traduzione o correzione immediata di un documento Latex
+Generazione di annotazioni in batch | [Plugin di funzioni] Generazione automatica delle annotazioni di funzione con un solo clic
+[Traduzione cinese-inglese di Markdown](https://www.bilibili.com/video/BV1yo4y157jV/) | [Plugin di funzioni] Hai letto il [README](https://github.com/binary-husky/chatgpt_academic/blob/master/docs/README_EN.md) delle cinque lingue sopra?
+Generazione di report di analisi di chat | [Plugin di funzioni] Generazione automatica di un rapporto di sintesi dopo l'esecuzione
+[Funzione di traduzione di tutto il documento PDF](https://www.bilibili.com/video/BV1KT411x7Wn) | [Plugin di funzioni] Estrarre il titolo e il sommario dell'articolo PDF + tradurre l'intero testo (multithreading)
+[Assistente di Arxiv](https://www.bilibili.com/video/BV1LM4y1279X) | [Plugin di funzioni] Inserire l'URL dell'articolo di Arxiv e tradurre il sommario con un clic + scaricare il PDF
+[Assistente integrato di Google Scholar](https://www.bilibili.com/video/BV19L411U7ia) | [Plugin di funzioni] Con qualsiasi URL di pagina di ricerca di Google Scholar, lascia che GPT ti aiuti a scrivere il tuo [relatedworks](https://www.bilibili.com/video/BV1GP411U7Az/)
+Aggregazione delle informazioni su Internet + GPT | [Plugin di funzioni] Fai in modo che GPT rilevi le informazioni su Internet prima di rispondere alle domande, senza mai diventare obsolete
+Visualizzazione di formule/img/tabelle | È possibile visualizzare un'equazione in forma [tex e render](https://user-images.githubusercontent.com/96192199/230598842-1d7fcddd-815d-40ee-af60-baf488a199df.png) contemporaneamente, supporta equazioni e evidenziazione del codice
+Supporto per plugin di funzioni multithreading | Supporto per chiamata multithreaded di chatgpt, elaborazione con un clic di grandi quantità di testo o di un programma
+Avvia il tema di gradio [scuro](https://github.com/binary-husky/chatgpt_academic/issues/173) | Aggiungere ```/?__theme=dark``` dopo l'URL del browser per passare a un tema scuro
+Supporto per maggiori modelli LLM, supporto API2D | Sentirsi serviti simultaneamente da GPT3.5, GPT4, [Tsinghua ChatGLM](https://github.com/THUDM/ChatGLM-6B), [Fudan MOSS](https://github.com/OpenLMLab/MOSS) deve essere una grande sensazione, giusto?
+Ulteriori modelli LLM supportat,i supporto per l'implementazione di Huggingface | Aggiunta di un'interfaccia Newbing (Nuovo Bing), introdotta la compatibilità con Tsinghua [Jittorllms](https://github.com/Jittor/JittorLLMs), [LLaMA](https://github.com/facebookresearch/llama), [RWKV](https://github.com/BlinkDL/ChatRWKV) e [PanGu-α](https://openi.org.cn/pangu/)
+Ulteriori dimostrazioni di nuove funzionalità (generazione di immagini, ecc.)... | Vedere la fine di questo documento...
+
+- Nuova interfaccia (modificare l'opzione LAYOUT in `config.py` per passare dal layout a sinistra e a destra al layout superiore e inferiore)
+
+

+
Sei un traduttore professionista di paper accademici.
+
+- Tutti i pulsanti vengono generati dinamicamente leggendo il file functional.py, e aggiungerci nuove funzionalità è facile, liberando la clipboard.
+
+

+
+
+- Revisione/Correzione
+
+

+
+
+- Se l'output contiene una formula, viene visualizzata sia come testo che come formula renderizzata, per facilitare la copia e la visualizzazione.
+
+

+
+
+- Non hai tempo di leggere il codice del progetto? Passa direttamente a chatgpt e chiedi informazioni.
+
+

+
+
+- Chiamata mista di vari modelli di lingua di grandi dimensioni (ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4)
+
+

+
+
+---
+# Installazione
+## Installazione - Metodo 1: Esecuzione diretta (Windows, Linux o MacOS)
+
+1. Scarica il progetto
+```sh
+git clone https://github.com/binary-husky/chatgpt_academic.git
+cd chatgpt_academic
+```
+
+2. Configura API_KEY
+
+In `config.py`, configura la tua API KEY e altre impostazioni, [configs for special network environments](https://github.com/binary-husky/gpt_academic/issues/1).
+
+(N.B. Quando il programma viene eseguito, verifica prima se esiste un file di configurazione privato chiamato `config_private.py` e sovrascrive le stesse configurazioni in `config.py`. Pertanto, se capisci come funziona la nostra logica di lettura della configurazione, ti consigliamo vivamente di creare un nuovo file di configurazione chiamato `config_private.py` accanto a `config.py`, e spostare (copiare) le configurazioni di `config.py` in `config_private.py`. 'config_private.py' non è sotto la gestione di git e può proteggere ulteriormente le tue informazioni personali. NB Il progetto supporta anche la configurazione della maggior parte delle opzioni tramite "variabili d'ambiente". La sintassi della variabile d'ambiente è descritta nel file `docker-compose`. Priorità di lettura: "variabili d'ambiente" > "config_private.py" > "config.py")
+
+
+3. Installa le dipendenze
+```sh
+# (Scelta I: se sei familiare con python) (python 3.9 o superiore, più nuovo è meglio), N.B.: utilizza il repository ufficiale pip o l'aliyun pip repository, metodo temporaneo per cambiare il repository: python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
+python -m pip install -r requirements.txt
+
+# (Scelta II: se non conosci Python) utilizza anaconda, il processo è simile (https://www.bilibili.com/video/BV1rc411W7Dr):
+conda create -n gptac_venv python=3.11 # crea l'ambiente anaconda
+conda activate gptac_venv # attiva l'ambiente anaconda
+python -m pip install -r requirements.txt # questo passaggio funziona allo stesso modo dell'installazione con pip
+```
+
+
Se si desidera supportare ChatGLM di Tsinghua/MOSS di Fudan come backend, fare clic qui per espandere
+
+
+【Passaggio facoltativo】 Se si desidera supportare ChatGLM di Tsinghua/MOSS di Fudan come backend, è necessario installare ulteriori dipendenze (prerequisiti: conoscenza di Python, esperienza con Pytorch e computer sufficientemente potente):
+```sh
+# 【Passaggio facoltativo I】 Supporto a ChatGLM di Tsinghua. Note su ChatGLM di Tsinghua: in caso di errore "Call ChatGLM fail 不能正常加载ChatGLM的参数" , fare quanto segue: 1. Per impostazione predefinita, viene installata la versione di torch + cpu; per usare CUDA, è necessario disinstallare torch e installare nuovamente torch + cuda; 2. Se non è possibile caricare il modello a causa di una configurazione insufficiente del computer, è possibile modificare la precisione del modello in request_llm/bridge_chatglm.py, cambiando AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) in AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
+python -m pip install -r request_llm/requirements_chatglm.txt
+
+# 【Passaggio facoltativo II】 Supporto a MOSS di Fudan
+python -m pip install -r request_llm/requirements_moss.txt
+git clone https://github.com/OpenLMLab/MOSS.git request_llm/moss # Si prega di notare che quando si esegue questa riga di codice, si deve essere nella directory radice del progetto
+
+# 【Passaggio facoltativo III】 Assicurati che il file di configurazione config.py includa tutti i modelli desiderati, al momento tutti i modelli supportati sono i seguenti (i modelli della serie jittorllms attualmente supportano solo la soluzione docker):
+AVAIL_LLM_MODELS = ["gpt-3.5-turbo", "api2d-gpt-3.5-turbo", "gpt-4", "api2d-gpt-4", "chatglm", "newbing", "moss"] # + ["jittorllms_rwkv", "jittorllms_pangualpha", "jittorllms_llama"]
+```
+
+
+
+
+
+
+4. Esegui
+```sh
+python main.py
+```5. Plugin di test delle funzioni
+```
+- Funzione plugin di test (richiede una risposta gpt su cosa è successo oggi in passato), puoi utilizzare questa funzione come template per implementare funzionalità più complesse
+ Clicca su "[Demo del plugin di funzione] Oggi nella storia"
+```
+
+## Installazione - Metodo 2: Utilizzo di Docker
+
+1. Solo ChatGPT (consigliato per la maggior parte delle persone)
+
+``` sh
+git clone https://github.com/binary-husky/chatgpt_academic.git # scarica il progetto
+cd chatgpt_academic # entra nel percorso
+nano config.py # con un qualsiasi editor di testo, modifica config.py configurando "Proxy", "API_KEY" e "WEB_PORT" (ad esempio 50923)
+docker build -t gpt-academic . # installa
+
+#(ultimo passaggio - selezione 1) In un ambiente Linux, utilizzare '--net=host' è più conveniente e veloce
+docker run --rm -it --net=host gpt-academic
+#(ultimo passaggio - selezione 2) In un ambiente MacOS/Windows, l'opzione -p può essere utilizzata per esporre la porta del contenitore (ad es. 50923) alla porta della macchina
+docker run --rm -it -e WEB_PORT=50923 -p 50923:50923 gpt-academic
+```
+
+2. ChatGPT + ChatGLM + MOSS (richiede familiarità con Docker)
+
+``` sh
+# Modifica docker-compose.yml, elimina i piani 1 e 3, mantieni il piano 2. Modifica la configurazione del piano 2 in docker-compose.yml, si prega di fare riferimento alle relative annotazioni
+docker-compose up
+```
+
+3. ChatGPT + LLAMA + Pangu + RWKV (richiede familiarità con Docker)
+
+``` sh
+# Modifica docker-compose.yml, elimina i piani 1 e 2, mantieni il piano 3. Modifica la configurazione del piano 3 in docker-compose.yml, si prega di fare riferimento alle relative annotazioni
+docker-compose up
+```
+
+
+## Installazione - Metodo 3: Altre modalità di distribuzione
+
+1. Come utilizzare un URL di reindirizzamento / AzureAPI Cloud Microsoft
+Configura API_URL_REDIRECT seguendo le istruzioni nel file `config.py`.
+
+2. Distribuzione su un server cloud remoto (richiede conoscenze ed esperienza di server cloud)
+Si prega di visitare [wiki di distribuzione-1] (https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
+
+3. Utilizzo di WSL2 (Windows Subsystem for Linux)
+Si prega di visitare [wiki di distribuzione-2] (https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
+
+4. Come far funzionare ChatGPT all'interno di un sottodominio (ad es. `http://localhost/subpath`)
+Si prega di visitare [Istruzioni per l'esecuzione con FastAPI] (docs/WithFastapi.md)
+
+5. Utilizzo di docker-compose per l'esecuzione
+Si prega di leggere il file docker-compose.yml e seguire le istruzioni fornite.
+
+---
+# Uso avanzato
+## Personalizzazione dei pulsanti / Plugin di funzione personalizzati
+
+1. Personalizzazione dei pulsanti (scorciatoie accademiche)
+Apri `core_functional.py` con qualsiasi editor di testo e aggiungi la voce seguente, quindi riavvia il programma (se il pulsante è già stato aggiunto con successo e visibile, il prefisso e il suffisso supportano la modifica in tempo reale, senza bisogno di riavviare il programma).
+
+ad esempio
+```
+"超级英译中": {
+ # Prefisso, verrà aggiunto prima del tuo input. Ad esempio, descrivi la tua richiesta, come tradurre, spiegare il codice, correggere errori, ecc.
+ "Prefix": "Per favore traduci questo testo in Cinese, e poi spiega tutti i termini tecnici nel testo con una tabella markdown:\n\n",
+
+ # Suffisso, verrà aggiunto dopo il tuo input. Ad esempio, con il prefisso puoi circondare il tuo input con le virgolette.
+ "Suffix": "",
+},
+```
+
+

+
+
+2. Plugin di funzione personalizzati
+
+Scrivi plugin di funzione personalizzati e esegui tutte le attività che desideri o non hai mai pensato di fare.
+La difficoltà di scrittura e debug dei plugin del nostro progetto è molto bassa. Se si dispone di una certa conoscenza di base di Python, è possibile realizzare la propria funzione del plugin seguendo il nostro modello. Per maggiori dettagli, consultare la [guida al plugin per funzioni] (https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97).
+
+---
+# Ultimo aggiornamento
+## Nuove funzionalità dinamiche1. Funzionalità di salvataggio della conversazione. Nell'area dei plugin della funzione, fare clic su "Salva la conversazione corrente" per salvare la conversazione corrente come file html leggibile e ripristinabile, inoltre, nell'area dei plugin della funzione (menu a discesa), fare clic su "Carica la cronologia della conversazione archiviata" per ripristinare la conversazione precedente. Suggerimento: fare clic su "Carica la cronologia della conversazione archiviata" senza specificare il file consente di visualizzare la cache degli archivi html di cronologia, fare clic su "Elimina tutti i record di cronologia delle conversazioni locali" per eliminare tutte le cache degli archivi html.
+
+

+
+
+2. Generazione di rapporti. La maggior parte dei plugin genera un rapporto di lavoro dopo l'esecuzione.
+
+
+3. Progettazione modulare delle funzioni, semplici interfacce ma in grado di supportare potenti funzionalità.
+
+

+

+
+
+4. Questo è un progetto open source che può "tradursi da solo".
+
+

+
+
+5. Tradurre altri progetti open source è semplice.
+
+
+
+
+
+

+
+
+6. Piccola funzione decorativa per [live2d](https://github.com/fghrsh/live2d_demo) (disattivata per impostazione predefinita, è necessario modificare `config.py`).
+
+

+
+
+7. Supporto del grande modello linguistico MOSS
+
+

+
+
+8. Generazione di immagini OpenAI
+
+

+
+
+9. Analisi e sintesi audio OpenAI
+
+

+
+
+10. Verifica completa dei testi in LaTeX
+
+

+
+
+
+## Versione:
+- versione 3.5(Todo): utilizzo del linguaggio naturale per chiamare tutti i plugin di funzioni del progetto (alta priorità)
+- versione 3.4(Todo): supporto multi-threading per il grande modello linguistico locale Chatglm
+- versione 3.3: +funzionalità di sintesi delle informazioni su Internet
+- versione 3.2: i plugin di funzioni supportano più interfacce dei parametri (funzionalità di salvataggio della conversazione, lettura del codice in qualsiasi lingua + richiesta simultanea di qualsiasi combinazione di LLM)
+- versione 3.1: supporto per interrogare contemporaneamente più modelli gpt! Supporto api2d, bilanciamento del carico per più apikey
+- versione 3.0: supporto per Chatglm e altri piccoli LLM
+- versione 2.6: ristrutturazione della struttura del plugin, miglioramento dell'interattività, aggiunta di più plugin
+- versione 2.5: auto-aggiornamento, risoluzione del problema di testo troppo lungo e overflow del token durante la sintesi di grandi progetti di ingegneria
+- versione 2.4: (1) funzionalità di traduzione dell'intero documento in formato PDF aggiunta; (2) funzionalità di scambio dell'area di input aggiunta; (3) opzione di layout verticale aggiunta; (4) ottimizzazione della funzione di plugin multi-threading.
+- versione 2.3: miglioramento dell'interattività multi-threading
+- versione 2.2: i plugin di funzioni supportano l'hot-reload
+- versione 2.1: layout ripiegabile
+- versione 2.0: introduzione di plugin di funzioni modulari
+- versione 1.0: funzione di basegpt_academic sviluppatori gruppo QQ-2: 610599535
+
+- Problemi noti
+ - Alcuni plugin di traduzione del browser interferiscono con l'esecuzione del frontend di questo software
+ - La versione di gradio troppo alta o troppo bassa può causare diversi malfunzionamenti
+
+## Riferimenti e apprendimento
+
+```
+Il codice fa riferimento a molte altre eccellenti progettazioni di progetti, principalmente:
+
+# Progetto 1: ChatGLM-6B di Tsinghua:
+https://github.com/THUDM/ChatGLM-6B
+
+# Progetto 2: JittorLLMs di Tsinghua:
+https://github.com/Jittor/JittorLLMs
+
+# Progetto 3: Edge-GPT:
+https://github.com/acheong08/EdgeGPT
+
+# Progetto 4: ChuanhuChatGPT:
+https://github.com/GaiZhenbiao/ChuanhuChatGPT
+
+# Progetto 5: ChatPaper:
+https://github.com/kaixindelele/ChatPaper
+
+# Altro:
+https://github.com/gradio-app/gradio
+https://github.com/fghrsh/live2d_demo
+```
\ No newline at end of file
diff --git a/docs/README.md.Korean.md b/docs/README.md.Korean.md
new file mode 100644
index 0000000000000000000000000000000000000000..d94aaf1ac9ef5bc4699d3edf9b4b04733ef0eb92
--- /dev/null
+++ b/docs/README.md.Korean.md
@@ -0,0 +1,268 @@
+> **노트**
+>
+> 의존성을 설치할 때는 반드시 requirements.txt에서 **지정된 버전**을 엄격하게 선택하십시오.
+>
+> `pip install -r requirements.txt`
+
+#

GPT 학술 최적화 (GPT Academic)
+
+**이 프로젝트가 마음에 드신다면 Star를 주세요. 추가로 유용한 학술 단축키나 기능 플러그인이 있다면 이슈나 pull request를 남기세요. 이 프로젝트에 대한 [영어 |](docs/README_EN.md)[일본어 |](docs/README_JP.md)[한국어 |](https://github.com/mldljyh/ko_gpt_academic)[러시아어 |](docs/README_RS.md)[프랑스어](docs/README_FR.md)로 된 README도 있습니다.
+GPT를 이용하여 프로젝트를 임의의 언어로 번역하려면 [`multi_language.py`](multi_language.py)를 읽고 실행하십시오. (실험적)
+
+> **노트**
+>
+> 1. 파일을 읽기 위해 **빨간색**으로 표시된 기능 플러그인 (버튼) 만 지원됩니다. 일부 플러그인은 플러그인 영역의 **드롭다운 메뉴**에 있습니다. 또한 새로운 플러그인은 **가장 높은 우선순위**로 환영하며 처리합니다!
+>
+> 2. 이 프로젝트의 각 파일의 기능을 [`self_analysis.md`](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A)에서 자세히 설명합니다. 버전이 업데이트 됨에 따라 관련된 기능 플러그인을 클릭하고 GPT를 호출하여 프로젝트의 자체 분석 보고서를 다시 생성할 수도 있습니다. 자주 묻는 질문은 [`위키`](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98)에서 볼 수 있습니다. [설치 방법](#installation).
+>
+> 3. 이 프로젝트는 국내 언어 모델 chatglm과 RWKV, 판고 등의 시도와 호환 가능합니다. 여러 개의 api-key를 지원하며 설정 파일에 "API_KEY="openai-key1,openai-key2,api2d-key3""와 같이 작성할 수 있습니다. `API_KEY`를 임시로 변경해야하는 경우 입력 영역에 임시 `API_KEY`를 입력 한 후 엔터 키를 누르면 즉시 적용됩니다.
+
+
기능 | 설명
+--- | ---
+원 키워드 | 원 키워드 및 논문 문법 오류를 찾는 기능 지원
+한-영 키워드 | 한-영 키워드 지원
+코드 설명 | 코드 표시, 코드 설명, 코드 생성, 코드에 주석 추가
+[사용자 정의 바로 가기 키](https://www.bilibili.com/video/BV14s4y1E7jN) | 사용자 정의 바로 가기 키 지원
+모듈식 설계 | 강력한[함수 플러그인](https://github.com/binary-husky/chatgpt_academic/tree/master/crazy_functions) 지원, 플러그인이 [램 업데이트](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)를 지원합니다.
+[자체 프로그램 분석](https://www.bilibili.com/video/BV1cj411A7VW) | [함수 플러그인] [원 키 우드] 프로젝트 소스 코드의 내용을 이해하는 기능을 제공
+[프로그램 분석](https://www.bilibili.com/video/BV1cj411A7VW) | [함수 플러그인] 프로젝트 트리를 분석할 수 있습니다 (Python/C/C++/Java/Lua/...)
+논문 읽기, 번역 | [함수 플러그인] LaTex/PDF 논문의 전문을 읽고 요약을 생성합니다.
+LaTeX 텍스트[번역](https://www.bilibili.com/video/BV1nk4y1Y7Js/), [원 키워드](https://www.bilibili.com/video/BV1FT411H7c5/) | [함수 플러그인] LaTeX 논문의 번역 또는 개량을 위해 일련의 모드를 번역할 수 있습니다.
+대량의 주석 생성 | [함수 플러그인] 함수 코멘트를 대량으로 생성할 수 있습니다.
+Markdown 한-영 번역 | [함수 플러그인] 위의 5 종 언어의 [README](https://github.com/binary-husky/chatgpt_academic/blob/master/docs/README_EN.md)를 볼 수 있습니다.
+chat 분석 보고서 생성 | [함수 플러그인] 수행 후 요약 보고서를 자동으로 생성합니다.
+[PDF 논문 번역](https://www.bilibili.com/video/BV1KT411x7Wn) | [함수 플러그인] PDF 논문이 제목 및 요약을 추출한 후 번역됩니다. (멀티 스레드)
+[Arxiv 도우미](https://www.bilibili.com/video/BV1LM4y1279X) | [함수 플러그인] Arxiv 논문 URL을 입력하면 요약을 번역하고 PDF를 다운로드 할 수 있습니다.
+[Google Scholar 통합 도우미](https://www.bilibili.com/video/BV19L411U7ia) | [함수 플러그인] Google Scholar 검색 페이지 URL을 제공하면 gpt가 [Related Works 작성](https://www.bilibili.com/video/BV1GP411U7Az/)을 도와줍니다.
+인터넷 정보 집계+GPT | [함수 플러그인] 먼저 GPT가 인터넷에서 정보를 수집하고 질문에 대답 할 수 있도록합니다. 정보가 절대적으로 구식이 아닙니다.
+수식/이미지/표 표시 | 급여, 코드 강조 기능 지원
+멀티 스레드 함수 플러그인 지원 | Chatgpt를 여러 요청에서 실행하여 [대량의 텍스트](https://www.bilibili.com/video/BV1FT411H7c5/) 또는 프로그램을 처리 할 수 있습니다.
+다크 그라디오 테마 시작 | 어둡게 주제를 변경하려면 브라우저 URL 끝에 ```/?__theme=dark```을 추가하면됩니다.
+[다중 LLM 모델](https://www.bilibili.com/video/BV1wT411p7yf) 지원, [API2D](https://api2d.com/) 인터페이스 지원됨 | GPT3.5, GPT4, [Tsinghua ChatGLM](https://github.com/THUDM/ChatGLM-6B), [Fudan MOSS](https://github.com/OpenLMLab/MOSS)가 모두 동시에 작동하는 것처럼 느낄 수 있습니다!
+LLM 모델 추가 및[huggingface 배치](https://huggingface.co/spaces/qingxu98/gpt-academic) 지원 | 새 Bing 인터페이스 (새 Bing) 추가, Clearing House [Jittorllms](https://github.com/Jittor/JittorLLMs) 지원 [LLaMA](https://github.com/facebookresearch/llama), [RWKV](https://github.com/BlinkDL/ChatRWKV) 및 [盘古α](https://openi.org.cn/pangu/)
+기타 새로운 기능 (이미지 생성 등) ... | 이 문서의 끝부분을 참조하세요. ...- 모든 버튼은 functional.py를 동적으로 읽어와서 사용자 정의 기능을 자유롭게 추가할 수 있으며, 클립 보드를 해제합니다.
+
+
+
+
+- 검수/오타 교정
+
+
+
+
+- 출력에 수식이 포함되어 있으면 텍스와 렌더링의 형태로 동시에 표시되어 복사 및 읽기가 용이합니다.
+
+
+
+
+- 프로젝트 코드를 볼 시간이 없습니까? 전체 프로젝트를 chatgpt에 직접 표시하십시오
+
+
+
+
+- 다양한 대형 언어 모델 범용 요청 (ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4)
+
+
+
+
+---
+# 설치
+## Installation-Method 1: Run directly (Windows, Linux or MacOS)
+
+1. 프로젝트 다운로드
+```sh
+git clone https://github.com/binary-husky/chatgpt_academic.git
+cd chatgpt_academic
+```
+
+2. API_KEY 구성
+
+`config.py`에서 API KEY 등 설정을 구성합니다. [특별한 네트워크 환경 설정](https://github.com/binary-husky/gpt_academic/issues/1) .
+
+(P.S. 프로그램이 실행될 때, 이름이 `config_private.py`인 기밀 설정 파일이 있는지 우선적으로 확인하고 해당 설정으로 `config.py`의 동일한 이름의 설정을 덮어씁니다. 따라서 구성 읽기 논리를 이해할 수 있다면, `config.py` 옆에 `config_private.py`라는 새 구성 파일을 만들고 `config.py`의 구성을 `config_private.py`로 이동(복사)하는 것이 좋습니다. `config_private.py`는 git으로 관리되지 않으며 개인 정보를 더 안전하게 보호할 수 있습니다. P.S. 프로젝트는 또한 대부분의 옵션을 `환경 변수`를 통해 설정할 수 있으며, `docker-compose` 파일을 참조하여 환경 변수 작성 형식을 확인할 수 있습니다. 우선순위: `환경 변수` > `config_private.py` > `config.py`)
+
+
+3. 의존성 설치
+```sh
+# (I 선택: 기존 python 경험이 있다면) (python 버전 3.9 이상, 최신 버전이 좋습니다), 참고: 공식 pip 소스 또는 알리 pip 소스 사용, 일시적인 교체 방법: python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
+python -m pip install -r requirements.txt
+
+# (II 선택: Python에 익숙하지 않은 경우) anaconda 사용 방법은 비슷함(https://www.bilibili.com/video/BV1rc411W7Dr):
+conda create -n gptac_venv python=3.11 # anaconda 환경 만들기
+conda activate gptac_venv # anaconda 환경 활성화
+python -m pip install -r requirements.txt # 이 단계도 pip install의 단계와 동일합니다.
+```
+
+
추가지원을 위해 Tsinghua ChatGLM / Fudan MOSS를 사용해야하는 경우 지원을 클릭하여 이 부분을 확장하세요.
+
+
+[Tsinghua ChatGLM] / [Fudan MOSS]를 백엔드로 사용하려면 추가적인 종속성을 설치해야합니다 (전제 조건 : Python을 이해하고 Pytorch를 사용한 적이 있으며, 컴퓨터가 충분히 강력한 경우) :
+```sh
+# [선택 사항 I] Tsinghua ChatGLM을 지원합니다. Tsinghua ChatGLM에 대한 참고사항 : "Call ChatGLM fail cannot load ChatGLM parameters normally" 오류 발생시 다음 참조:
+# 1 : 기본 설치된 것들은 torch + cpu 버전입니다. cuda를 사용하려면 torch를 제거한 다음 torch + cuda를 다시 설치해야합니다.
+# 2 : 모델을 로드할 수 없는 기계 구성 때문에, AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)를
+# AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)로 변경합니다.
+python -m pip install -r request_llm/requirements_chatglm.txt
+
+# [선택 사항 II] Fudan MOSS 지원
+python -m pip install -r request_llm/requirements_moss.txt
+git clone https://github.com/OpenLMLab/MOSS.git request_llm/moss # 다음 코드 줄을 실행할 때 프로젝트 루트 경로에 있어야합니다.
+
+# [선택 사항III] AVAIL_LLM_MODELS config.py 구성 파일에 기대하는 모델이 포함되어 있는지 확인하십시오.
+# 현재 지원되는 전체 모델 :
+AVAIL_LLM_MODELS = ["gpt-3.5-turbo", "api2d-gpt-3.5-turbo", "gpt-4", "api2d-gpt-4", "chatglm", "newbing", "moss"] # + ["jittorllms_rwkv", "jittorllms_pangualpha", "jittorllms_llama"]
+```
+
+
+
+
+
+
+4. 실행
+```sh
+python main.py
+```5. 테스트 함수 플러그인
+```
+- 테스트 함수 플러그인 템플릿 함수 (GPT에게 오늘의 역사에서 무슨 일이 일어났는지 대답하도록 요청)를 구현하는 데 사용할 수 있습니다. 이 함수를 기반으로 더 복잡한 기능을 구현할 수 있습니다.
+ "[함수 플러그인 템플릿 데모] 오늘의 역사"를 클릭하세요.
+```
+
+## 설치 - 방법 2 : 도커 사용
+
+1. ChatGPT 만 (대부분의 사람들이 선택하는 것을 권장합니다.)
+
+``` sh
+git clone https://github.com/binary-husky/chatgpt_academic.git # 다운로드
+cd chatgpt_academic # 경로 이동
+nano config.py # 아무 텍스트 에디터로 config.py를 열고 "Proxy","API_KEY","WEB_PORT" (예 : 50923) 등을 구성합니다.
+docker build -t gpt-academic . # 설치
+
+#(마지막 단계-1 선택) Linux 환경에서는 --net=host를 사용하면 더 편리합니다.
+docker run --rm -it --net=host gpt-academic
+#(마지막 단계-2 선택) macOS / windows 환경에서는 -p 옵션을 사용하여 컨테이너의 포트 (예 : 50923)를 호스트의 포트로 노출해야합니다.
+docker run --rm -it -e WEB_PORT=50923 -p 50923:50923 gpt-academic
+```
+
+2. ChatGPT + ChatGLM + MOSS (Docker에 익숙해야합니다.)
+
+``` sh
+#docker-compose.yml을 수정하여 계획 1 및 계획 3을 삭제하고 계획 2를 유지합니다. docker-compose.yml에서 계획 2의 구성을 수정하면 됩니다. 주석을 참조하십시오.
+docker-compose up
+```
+
+3. ChatGPT + LLAMA + Pangu + RWKV (Docker에 익숙해야합니다.)
+``` sh
+#docker-compose.yml을 수정하여 계획 1 및 계획 2을 삭제하고 계획 3을 유지합니다. docker-compose.yml에서 계획 3의 구성을 수정하면 됩니다. 주석을 참조하십시오.
+docker-compose up
+```
+
+
+## 설치 - 방법 3 : 다른 배치 방법
+
+1. 리버스 프록시 URL / Microsoft Azure API 사용 방법
+API_URL_REDIRECT를 `config.py`에 따라 구성하면됩니다.
+
+2. 원격 클라우드 서버 배치 (클라우드 서버 지식과 경험이 필요합니다.)
+[배치위키-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)에 방문하십시오.
+
+3. WSL2 사용 (Windows Subsystem for Linux 하위 시스템)
+[배치 위키-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)에 방문하십시오.
+
+4. 2 차 URL (예 : `http : //localhost/subpath`)에서 실행하는 방법
+[FastAPI 실행 설명서] (docs / WithFastapi.md)를 참조하십시오.
+
+5. docker-compose 실행
+docker-compose.yml을 읽은 후 지시 사항에 따라 작업하십시오.
+---
+# 고급 사용법
+## 사용자 정의 바로 가기 버튼 / 사용자 정의 함수 플러그인
+
+1. 사용자 정의 바로 가기 버튼 (학술 바로 가기)
+임의의 텍스트 편집기로 'core_functional.py'를 엽니다. 엔트리 추가, 그런 다음 프로그램을 다시 시작하면됩니다. (버튼이 이미 추가되어 보이고 접두사, 접미사가 모두 변수가 효과적으로 수정되면 프로그램을 다시 시작하지 않아도됩니다.)
+예 :
+```
+"超级英译中": {
+ # 접두사. 당신이 요구하는 것을 설명하는 데 사용됩니다. 예를 들어 번역, 코드를 설명, 다듬기 등
+ "Prefix": "下面翻译成中文,然后用一个 markdown 表格逐一解释文中出现的专有名词:\n\n",
+
+ # 접미사는 입력 내용 앞뒤에 추가됩니다. 예를 들어 전위를 사용하여 입력 내용을 따옴표로 묶는데 사용할 수 있습니다.
+ "Suffix": "",
+},
+```
+
+
+
+
+2. 사용자 지정 함수 플러그인
+강력한 함수 플러그인을 작성하여 원하는 작업을 수행하십시오.
+이 프로젝트의 플러그인 작성 및 디버깅 난이도는 매우 낮으며, 일부 파이썬 기본 지식만 있으면 제공된 템플릿을 모방하여 플러그인 기능을 구현할 수 있습니다. 자세한 내용은 [함수 플러그인 가이드]를 참조하십시오. (https://github.com/binary -husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E 4%BB%B6%E6%8C%87%E5%8D%97).
+---
+# 최신 업데이트
+## 새로운 기능 동향1. 대화 저장 기능.
+
+1. 함수 플러그인 영역에서 '현재 대화 저장'을 호출하면 현재 대화를 읽을 수 있고 복원 가능한 HTML 파일로 저장할 수 있습니다. 또한 함수 플러그인 영역(드롭다운 메뉴)에서 '대화 기록 불러오기'를 호출하면 이전 대화를 복원할 수 있습니다. 팁: 파일을 지정하지 않고 '대화 기록 불러오기'를 클릭하면 기록된 HTML 캐시를 볼 수 있으며 '모든 로컬 대화 기록 삭제'를 클릭하면 모든 HTML 캐시를 삭제할 수 있습니다.
+
+2. 보고서 생성. 대부분의 플러그인은 실행이 끝난 후 작업 보고서를 생성합니다.
+
+3. 모듈화 기능 설계, 간단한 인터페이스로도 강력한 기능을 지원할 수 있습니다.
+
+4. 자체 번역이 가능한 오픈 소스 프로젝트입니다.
+
+5. 다른 오픈 소스 프로젝트를 번역하는 것은 어렵지 않습니다.
+
+6. [live2d](https://github.com/fghrsh/live2d_demo) 장식 기능(기본적으로 비활성화되어 있으며 `config.py`를 수정해야 합니다.)
+
+7. MOSS 대 언어 모델 지원 추가
+
+8. OpenAI 이미지 생성
+
+9. OpenAI 음성 분석 및 요약
+
+10. LaTeX 전체적인 교정 및 오류 수정
+
+## 버전:
+- version 3.5 (TODO): 자연어를 사용하여 이 프로젝트의 모든 함수 플러그인을 호출하는 기능(우선순위 높음)
+- version 3.4(TODO): 로컬 대 모듈의 다중 스레드 지원 향상
+- version 3.3: 인터넷 정보 종합 기능 추가
+- version 3.2: 함수 플러그인이 더 많은 인수 인터페이스를 지원합니다.(대화 저장 기능, 임의의 언어 코드 해석 및 동시에 임의의 LLM 조합을 확인하는 기능)
+- version 3.1: 여러 개의 GPT 모델에 대한 동시 쿼리 지원! api2d 지원, 여러 개의 apikey 로드 밸런싱 지원
+- version 3.0: chatglm 및 기타 소형 llm의 지원
+- version 2.6: 플러그인 구조를 재구성하여 상호 작용성을 향상시켰습니다. 더 많은 플러그인을 추가했습니다.
+- version 2.5: 자체 업데이트, 전체 프로젝트를 요약할 때 텍스트가 너무 길어지고 토큰이 오버플로우되는 문제를 해결했습니다.
+- version 2.4: (1) PDF 전체 번역 기능 추가; (2) 입력 영역 위치 전환 기능 추가; (3) 수직 레이아웃 옵션 추가; (4) 다중 스레드 함수 플러그인 최적화.
+- version 2.3: 다중 스레드 상호 작용성 강화
+- version 2.2: 함수 플러그인 히트 리로드 지원
+- version 2.1: 접는 레이아웃 지원
+- version 2.0: 모듈화 함수 플러그인 도입
+- version 1.0: 기본 기능
+
+gpt_academic 개발자 QQ 그룹-2 : 610599535
+
+- 알려진 문제
+ - 일부 브라우저 번역 플러그인이이 소프트웨어의 프론트 엔드 작동 방식을 방해합니다.
+ - gradio 버전이 너무 높거나 낮으면 여러 가지 이상이 발생할 수 있습니다.
+
+## 참고 및 학습 자료
+
+```
+많은 우수 프로젝트의 디자인을 참고했습니다. 주요 항목은 다음과 같습니다.
+
+# 프로젝트 1 : Tsinghua ChatGLM-6B :
+https://github.com/THUDM/ChatGLM-6B
+
+# 프로젝트 2 : Tsinghua JittorLLMs:
+https://github.com/Jittor/JittorLLMs
+
+# 프로젝트 3 : Edge-GPT :
+https://github.com/acheong08/EdgeGPT
+
+# 프로젝트 4 : ChuanhuChatGPT:
+https://github.com/GaiZhenbiao/ChuanhuChatGPT
+
+# 프로젝트 5 : ChatPaper :
+https://github.com/kaixindelele/ChatPaper
+
+# 더 많은 :
+https://github.com/gradio-app/gradio
+https://github.com/fghrsh/live2d_demo
+```
\ No newline at end of file
diff --git a/docs/README.md.Portuguese.md b/docs/README.md.Portuguese.md
new file mode 100644
index 0000000000000000000000000000000000000000..816ced1993b05c84ec8a3cd84c42adf1c9757cd2
--- /dev/null
+++ b/docs/README.md.Portuguese.md
@@ -0,0 +1,320 @@
+> **Nota**
+>
+> Ao instalar as dependências, por favor, selecione rigorosamente as versões **especificadas** no arquivo requirements.txt.
+>
+> `pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/`
+>
+
+#

Otimização acadêmica GPT (GPT Academic)
+
+**Se você gostou deste projeto, por favor dê um Star. Se você criou atalhos acadêmicos mais úteis ou plugins funcionais, sinta-se livre para abrir uma issue ou pull request. Nós também temos um README em [Inglês|](README_EN.md)[日本語|](README_JP.md)[한국어|](https://github.com/mldljyh/ko_gpt_academic)[Русский|](README_RS.md)[Français](README_FR.md) traduzidos por este próprio projeto.
+Para traduzir este projeto para qualquer idioma com o GPT, leia e execute [`multi_language.py`](multi_language.py) (experimental).
+
+> **Nota**
+>
+> 1. Por favor, preste atenção que somente os plugins de funções (botões) com a cor **vermelha** podem ler arquivos. Alguns plugins estão localizados no **menu suspenso** na área de plugins. Além disso, nós damos as boas-vindas com a **maior prioridade** e gerenciamos quaisquer novos plugins PR!
+>
+> 2. As funções de cada arquivo neste projeto são detalhadas em [`self_analysis.md`](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A), auto-análises do projeto geradas pelo GPT também estão podem ser chamadas a qualquer momento ao clicar nos plugins relacionados. As perguntas frequentes estão resumidas no [`wiki`](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98). [Instruções de Instalação](#installation).
+>
+> 3. Este projeto é compatível com e incentiva o uso de modelos de linguagem nacionais, como chatglm e RWKV, Pangolin, etc. Suporta a coexistência de várias chaves de API e pode ser preenchido no arquivo de configuração como `API_KEY="openai-key1,openai-key2,api2d-key3"`. Quando precisar alterar temporariamente o `API_KEY`, basta digitar o `API_KEY` temporário na área de entrada e pressionar Enter para que ele entre em vigor.
+
+
Funcionalidade | Descrição
+--- | ---
+Um clique de polimento | Suporte a um clique polimento, um clique encontrar erros de gramática no artigo
+Tradução chinês-inglês de um clique | Tradução chinês-inglês de um clique
+Explicação de código de um único clique | Exibir código, explicar código, gerar código, adicionar comentários ao código
+[Teclas de atalho personalizadas](https://www.bilibili.com/video/BV14s4y1E7jN) | Suporte a atalhos personalizados
+Projeto modular | Suporte para poderosos plugins[de função personalizada](https://github.com/binary-husky/chatgpt_academic/tree/master/crazy_functions), os plugins suportam[hot-reload](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)
+[Análise automática do programa](https://www.bilibili.com/video/BV1cj411A7VW) | [Plugin de função][um clique para entender](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) o código-fonte do projeto
+[Análise do programa](https://www.bilibili.com/video/BV1cj411A7VW) | [Plugin de função] Um clique pode analisar a árvore de projetos do Python/C/C++/Java/Lua/...
+Leitura de artigos, [tradução](https://www.bilibili.com/video/BV1KT411x7Wn) de artigos | [Plugin de função] um clique para interpretar o resumo de artigos LaTeX/PDF e gerar resumo
+Tradução completa LATEX, polimento|[Plugin de função] Uma clique para traduzir ou polir um artigo LATEX
+Geração em lote de comentários | [Plugin de função] Um clique gera comentários de função em lote
+[Tradução chinês-inglês](https://www.bilibili.com/video/BV1yo4y157jV/) markdown | [Plugin de função] Você viu o README em 5 linguagens acima?
+Relatório de análise de chat | [Plugin de função] Gera automaticamente um resumo após a execução
+[Funcionalidade de tradução de artigos completos em PDF](https://www.bilibili.com/video/BV1KT411x7Wn) | [Plugin de função] Extrai o título e o resumo do artigo PDF e traduz o artigo completo (multithread)
+Assistente arXiv | [Plugin de função] Insira o url do artigo arXiv para traduzir o resumo + baixar PDF
+Assistente de integração acadêmica do Google | [Plugin de função] Dê qualquer URL de página de pesquisa acadêmica do Google e deixe o GPT escrever[trabalhos relacionados](https://www.bilibili.com/video/BV1GP411U7Az/)
+Agregação de informações da Internet + GPT | [Plugin de função] Um clique para obter informações do GPT através da Internet e depois responde a perguntas para informações nunca ficarem desatualizadas
+Exibição de fórmulas/imagem/tabela | Pode exibir simultaneamente a forma de renderização e[TEX] das fórmulas, suporte a fórmulas e realce de código
+Suporte de plugins de várias linhas | Suporte a várias chamadas em linha do chatgpt, um clique para processamento[de massa de texto](https://www.bilibili.com/video/BV1FT411H7c5/) ou programa
+Tema gradio escuro | Adicione ``` /?__theme=dark``` ao final da url do navegador para ativar o tema escuro
+[Suporte para vários modelos LLM](https://www.bilibili.com/video/BV1wT411p7yf), suporte para a nova interface API2D | A sensação de ser atendido simultaneamente por GPT3.5, GPT4, [Chatglm THU](https://github.com/THUDM/ChatGLM-6B), [Moss Fudan](https://github.com/OpenLMLab/MOSS) deve ser ótima, certo?
+Mais modelos LLM incorporados, suporte para a implantação[huggingface](https://huggingface.co/spaces/qingxu98/gpt-academic) | Adicione interface Newbing (New Bing), suporte [JittorLLMs](https://github.com/Jittor/JittorLLMs) THU Introdução ao suporte do LLaMA, RWKV e Pan Gu Alpha
+Mais recursos novos mostrados (geração de imagens, etc.) ... | Consulte o final deste documento ...
+
+
+
+- Nova interface (Modifique a opção LAYOUT em `config.py` para alternar entre o layout esquerdo/direito e o layout superior/inferior)
+
+
+
- All buttons are dynamically generated by reading functional.py, and you can add custom functions at will, liberating the clipboard
+
+
+
+
+
+- Proofreading/errors correction
+
+
+
+
+
+
+- If the output contains formulas, it will be displayed in both tex and rendering format at the same time, which is convenient for copying and reading
+
+
+
+
+
+
+- Don't want to read the project code? Just show the whole project to chatgpt
+
+
+
+
+
+
+- Mix the use of multiple large language models (ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4)
+
+
+
+
+
+
+---
+# Instalação
+## Installation-Method 1: Run directly (Windows, Linux or MacOS)
+
+1. Download the project
+
+```sh
+git clone https://github.com/binary-husky/chatgpt_academic.git
+cd chatgpt_academic
+```
+
+2. Configure the API KEY
+
+In `config.py`, configure API KEY and other settings, [Special Network Environment Settings] (https://github.com/binary-husky/gpt_academic/issues/1).
+
+(P.S. When the program runs, it will first check whether there is a private configuration file named `config_private.py`, and use the configuration in it to cover the configuration with the same name in `config.py`. Therefore, if you can understand our configuration reading logic, we strongly recommend that you create a new configuration file named `config_private.py` next to `config.py`, and transfer (copy) the configuration in `config.py` to `config_private.py`. `config_private.py` is not controlled by git and can make your privacy information more secure. P.S. The project also supports configuring most options through `environment variables`. The writing format of environment variables is referenced to the `docker-compose` file. Reading priority: `environment variable` > `config_private.py` > `config.py`)
+
+
+3. Install dependencies
+
+```sh
+# (Option I: for those familiar with python)(python version is 3.9 or above, the newer the better), note: use the official pip source or the Alibaba pip source. Temporary solution for changing source: python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
+python -m pip install -r requirements.txt
+
+# (Option II: for those who are unfamiliar with python) use anaconda, the steps are also similar (https://www.bilibili.com/video/BV1rc411W7Dr):
+conda create -n gptac_venv python=3.11 # create anaconda environment
+conda activate gptac_venv # activate anaconda environment
+python -m pip install -r requirements.txt # This step is the same as the pip installation step
+```
+
+
If you need to support Tsinghua ChatGLM / Fudan MOSS as the backend, click to expand here
+
+
+[Optional Step] If you need to support Tsinghua ChatGLM / Fudan MOSS as the backend, you need to install more dependencies (prerequisite: familiar with Python + used Pytorch + computer configuration is strong):
+```sh
+# 【Optional Step I】support Tsinghua ChatGLM。Tsinghua ChatGLM Note: If you encounter a "Call ChatGLM fails cannot load ChatGLM parameters normally" error, refer to the following: 1: The default installed is torch+cpu version, and using cuda requires uninstalling torch and reinstalling torch+cuda; 2: If the model cannot be loaded due to insufficient computer configuration, you can modify the model accuracy in request_llm/bridge_chatglm.py and change AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) to AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True)
+python -m pip install -r request_llm/requirements_chatglm.txt
+
+# 【Optional Step II】support Fudan MOSS
+python -m pip install -r request_llm/requirements_moss.txt
+git clone https://github.com/OpenLMLab/MOSS.git request_llm/moss # Note: When executing this line of code, you must be in the project root path
+
+# 【Optional Step III】Make sure that the AVAIL_LLM_MODELS in the config.py configuration file contains the expected model. Currently, all supported models are as follows (jittorllms series currently only supports docker solutions):
+AVAIL_LLM_MODELS = ["gpt-3.5-turbo", "api2d-gpt-3.5-turbo", "gpt-4", "api2d-gpt-4", "chatglm", "newbing", "moss"] # + ["jittorllms_rwkv", "jittorllms_pangualpha", "jittorllms_llama"]
+```
+
+
+
+
+
+4. Run
+
+```sh
+python main.py
+```5. Plugin de Função de Teste
+```
+- Função de modelo de plug-in de teste (exige que o GPT responda ao que aconteceu hoje na história), você pode usar esta função como modelo para implementar funções mais complexas
+ Clique em "[Função de plug-in de modelo de demonstração] O que aconteceu hoje na história?"
+```
+
+## Instalação - Método 2: Usando o Docker
+
+1. Apenas ChatGPT (recomendado para a maioria das pessoas)
+
+``` sh
+git clone https://github.com/binary-husky/chatgpt_academic.git # Baixar o projeto
+cd chatgpt_academic # Entrar no caminho
+nano config.py # Editar config.py com qualquer editor de texto configurando "Proxy", "API_KEY" e "WEB_PORT" (por exemplo, 50923), etc.
+docker build -t gpt-academic . # Instale
+
+# (Ùltima etapa - escolha 1) Dentro do ambiente Linux, é mais fácil e rápido usar `--net=host`
+docker run --rm -it --net=host gpt-academic
+# (Última etapa - escolha 2) Em ambientes macOS/windows, você só pode usar a opção -p para expor a porta do contêiner (por exemplo, 50923) para a porta no host
+docker run --rm -it -e WEB_PORT=50923 -p 50923:50923 gpt-academic
+```
+
+2. ChatGPT + ChatGLM + MOSS (conhecimento de Docker necessário)
+
+``` sh
+# Edite o arquivo docker-compose.yml, remova as soluções 1 e 3, mantenha a solução 2, e siga as instruções nos comentários do arquivo
+docker-compose up
+```
+
+3. ChatGPT + LLAMA + Pangu + RWKV (conhecimento de Docker necessário)
+``` sh
+# Edite o arquivo docker-compose.yml, remova as soluções 1 e 2, mantenha a solução 3, e siga as instruções nos comentários do arquivo
+docker-compose up
+```
+
+
+## Instalação - Método 3: Outros Métodos de Implantação
+
+1. Como usar URLs de proxy inverso/microsoft Azure API
+Basta configurar o API_URL_REDIRECT de acordo com as instruções em `config.py`.
+
+2. Implantação em servidores em nuvem remotos (requer conhecimento e experiência de servidores em nuvem)
+Acesse [Wiki de implementação remota do servidor em nuvem](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
+
+3. Usando a WSL2 (sub-sistema do Windows para Linux)
+Acesse [Wiki da implantação da WSL2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
+
+4. Como executar em um subdiretório (ex. `http://localhost/subpath`)
+Acesse [Instruções de execução FastAPI](docs/WithFastapi.md)
+
+5. Execute usando o docker-compose
+Leia o arquivo docker-compose.yml e siga as instruções.
+
+# Uso Avançado
+## Customize novos botões de acesso rápido / plug-ins de função personalizados
+
+1. Personalizar novos botões de acesso rápido (atalhos acadêmicos)
+Abra `core_functional.py` em qualquer editor de texto e adicione os seguintes itens e reinicie o programa (Se o botão já foi adicionado e pode ser visto, prefixos e sufixos são compatíveis com modificações em tempo real e não exigem reinício do programa para ter efeito.)
+Por exemplo,
+```
+"Super Eng:": {
+ # Prefixo, será adicionado antes da sua entrada. Por exemplo, para descrever sua solicitação, como tradução, explicação de código, polimento, etc.
+ "Prefix": "Por favor, traduza o seguinte conteúdo para chinês e use uma tabela em Markdown para explicar termos próprios no texto: \n \n",
+
+ # Sufixo, será adicionado após a sua entrada. Por exemplo, emparelhado com o prefixo, pode colocar sua entrada entre aspas.
+ "Suffix": "",
+},
+```
+
+
+
+
+2. Personalizar plug-ins de função
+
+Escreva plug-ins de função poderosos para executar tarefas que você deseja e não pensava possível.
+A dificuldade geral de escrever e depurar plug-ins neste projeto é baixa e, se você tem algum conhecimento básico de python, pode implementar suas próprias funções sobre o modelo que fornecemos.
+Para mais detalhes, consulte o [Guia do plug-in de função.](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97).
+
+---
+# Última atualização
+## Novas funções dinâmicas.1. Função de salvamento de diálogo. Ao chamar o plug-in de função "Salvar diálogo atual", é possível salvar o diálogo atual em um arquivo html legível e reversível. Além disso, ao chamar o plug-in de função "Carregar arquivo de histórico de diálogo" no menu suspenso da área de plug-in, é possível restaurar uma conversa anterior. Dica: clicar em "Carregar arquivo de histórico de diálogo" sem especificar um arquivo permite visualizar o cache do arquivo html de histórico. Clicar em "Excluir todo o registro de histórico de diálogo local" permite excluir todo o cache de arquivo html.
+
+
+
+
+
+2. Geração de relatório. A maioria dos plug-ins gera um relatório de trabalho após a conclusão da execução.
+
+
+3. Design modular de funcionalidades, com interfaces simples, mas suporte a recursos poderosos
+
+
+
+
+
+4. Este é um projeto de código aberto que é capaz de "auto-traduzir-se".
+
+
+
+
+5. A tradução de outros projetos de código aberto é simples.
+
+
+
+
+
+
+
+
+6. Recursos decorativos para o [live2d](https://github.com/fghrsh/live2d_demo) (desativados por padrão, é necessário modificar o arquivo `config.py`)
+
+
+
+
+7. Suporte ao modelo de linguagem MOSS
+
+
+
+
+8. Geração de imagens pelo OpenAI
+
+
+
+
+9. Análise e resumo de áudio pelo OpenAI
+
+
+
+
+10. Revisão e correção de erros de texto em Latex.
+
+
+
+
+## Versão:
+- Versão 3.5(Todo): Usar linguagem natural para chamar todas as funções do projeto (prioridade alta)
+- Versão 3.4(Todo): Melhorar o suporte à multithread para o chatglm local
+- Versão 3.3: +Funções integradas de internet
+- Versão 3.2: Suporte a mais interfaces de parâmetros de plug-in (função de salvar diálogo, interpretação de códigos de várias linguagens, perguntas de combinações LLM arbitrárias ao mesmo tempo)
+- Versão 3.1: Suporte a perguntas a vários modelos de gpt simultaneamente! Suporte para api2d e balanceamento de carga para várias chaves api
+- Versão 3.0: Suporte ao chatglm e outros LLMs de pequeno porte
+- Versão 2.6: Refatoração da estrutura de plug-in, melhoria da interatividade e adição de mais plug-ins
+- Versão 2.5: Autoatualização, resolvendo problemas de token de texto excessivamente longo e estouro ao compilar grandes projetos
+- Versão 2.4: (1) Adição de funcionalidade de tradução de texto completo em PDF; (2) Adição de funcionalidade de mudança de posição da área de entrada; (3) Adição de opção de layout vertical; (4) Otimização de plug-ins de multithread.
+- Versão 2.3: Melhoria da interatividade de multithread
+- Versão 2.2: Suporte à recarga a quente de plug-ins
+- Versão 2.1: Layout dobrável
+- Versão 2.0: Introdução de plug-ins de função modular
+- Versão 1.0: Funcionalidades básicasgpt_academic desenvolvedores QQ grupo-2: 610599535
+
+- Problemas conhecidos
+ - Extensões de tradução de alguns navegadores podem interferir na execução do front-end deste software
+ - Uma versão muito alta ou muito baixa do Gradio pode causar vários erros
+
+## Referências e Aprendizado
+
+```
+Foi feita referência a muitos projetos excelentes em código, principalmente:
+
+# Projeto1: ChatGLM-6B da Tsinghua:
+https://github.com/THUDM/ChatGLM-6B
+
+# Projeto2: JittorLLMs da Tsinghua:
+https://github.com/Jittor/JittorLLMs
+
+# Projeto3: Edge-GPT:
+https://github.com/acheong08/EdgeGPT
+
+# Projeto4: ChuanhuChatGPT:
+https://github.com/GaiZhenbiao/ChuanhuChatGPT
+
+# Projeto5: ChatPaper:
+https://github.com/kaixindelele/ChatPaper
+
+# Mais:
+https://github.com/gradio-app/gradio
+https://github.com/fghrsh/live2d_demo
+```
\ No newline at end of file
diff --git a/docs/README_EN.md b/docs/README_EN.md
index db214f5327b8cdcd84ed1c57390c3b24ba83d78f..65af23d7b2c989107a664d7bd3ef88cf7e55c7f7 100644
--- a/docs/README_EN.md
+++ b/docs/README_EN.md
@@ -2,204 +2,195 @@
>
> This English README is automatically generated by the markdown translation plugin in this project, and may not be 100% correct.
>
+> When installing dependencies, **please strictly select the versions** specified in requirements.txt.
+>
+> `pip install -r requirements.txt`
-#
ChatGPT Academic Optimization
+# GPT Academic Optimization (GPT Academic)
-**If you like this project, please give it a Star. If you've come up with more useful academic shortcuts or functional plugins, feel free to open an issue or pull request. We also have a [README in English](docs/README_EN.md) translated by this project itself.**
+**If you like this project, please give it a Star. If you've come up with more useful academic shortcuts or functional plugins, feel free to open an issue or pull request.
+To translate this project to arbitary language with GPT, read and run [`multi_language.py`](multi_language.py) (experimental).**
-> **Note**
->
-> 1. Please note that only **functions with red color** supports reading files, some functions are located in the **dropdown menu** of plugins. Additionally, we welcome and prioritize any new plugin PRs with **highest priority**!
->
-> 2. The functionality of each file in this project is detailed in the self-translation report [`self_analysis.md`](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) of the project. With the iteration of the version, you can also click on the relevant function plugins at any time to call GPT to regenerate the self-analysis report of the project. The FAQ summary is in the [`wiki`](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98) section.
+> Note:
>
-
+> 1. Please note that only the function plugins (buttons) marked in **red** support reading files. Some plugins are in the **drop-down menu** in the plugin area. We welcome and process any new plugins with the **highest priority**!
+> 2. The function of each file in this project is detailed in the self-translation analysis [`self_analysis.md`](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A). With version iteration, you can also click on related function plugins at any time to call GPT to regenerate the project's self-analysis report. Common questions are summarized in the [`wiki`](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98). [Installation method](#installation).
+> 3. This project is compatible with and encourages trying domestic large language models such as chatglm, RWKV, Pangu, etc. Multiple API keys are supported and can be filled in the configuration file like `API_KEY="openai-key1,openai-key2,api2d-key3"`. When temporarily changing `API_KEY`, enter the temporary `API_KEY` in the input area and press enter to submit, which will take effect.
-
+
Function | Description
--- | ---
-One-Click Polish | Supports one-click polishing and finding grammar errors in academic papers.
-One-Key Translation Between Chinese and English | One-click translation between Chinese and English.
-One-Key Code Interpretation | Can correctly display and interpret code.
-[Custom Shortcut Keys](https://www.bilibili.com/video/BV14s4y1E7jN) | Supports custom shortcut keys.
-[Configure Proxy Server](https://www.bilibili.com/video/BV1rc411W7Dr) | Supports configuring proxy servers.
-Modular Design | Supports custom high-order function plugins and [function plugins], and plugins support [hot updates](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97).
-[Self-programming Analysis](https://www.bilibili.com/video/BV1cj411A7VW) | [Function Plugin] [One-Key Read] (https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) The source code of this project is analyzed.
-[Program Analysis](https://www.bilibili.com/video/BV1cj411A7VW) | [Function Plugin] One-click can analyze the project tree of other Python/C/C++/Java/Lua/... projects
-Read the Paper | [Function Plugin] One-click interpretation of the full text of latex paper and generation of abstracts
-Latex Full Text Translation, Proofreading | [Function Plugin] One-click translation or proofreading of latex papers.
-Batch Comment Generation | [Function Plugin] One-click batch generation of function comments
-Chat Analysis Report Generation | [Function Plugin] After running, an automatic summary report will be generated
-[Arxiv Assistant](https://www.bilibili.com/video/BV1LM4y1279X) | [Function Plugin] Enter the arxiv article url to translate the abstract and download the PDF with one click
-[Full-text Translation Function of PDF Paper](https://www.bilibili.com/video/BV1KT411x7Wn) | [Function Plugin] Extract the title & abstract of the PDF paper + translate the full text (multithreading)
-[Google Scholar Integration Assistant](https://www.bilibili.com/video/BV19L411U7ia) | [Function Plugin] Given any Google Scholar search page URL, let gpt help you choose interesting articles.
-Formula / Picture / Table Display | Can display both the tex form and the rendering form of formulas at the same time, support formula and code highlighting
-Multithreaded Function Plugin Support | Supports multi-threaded calling chatgpt, one-click processing of massive text or programs
-Start Dark Gradio [Theme](https://github.com/binary-husky/chatgpt_academic/issues/173) | Add ```/?__dark-theme=true``` at the end of the browser url to switch to dark theme
-[Multiple LLM Models](https://www.bilibili.com/video/BV1wT411p7yf) support, [API2D](https://api2d.com/) interface support | It must feel nice to be served by both GPT3.5, GPT4, and [Tsinghua ChatGLM](https://github.com/THUDM/ChatGLM-6B)!
-Huggingface non-Science Net [Online Experience](https://huggingface.co/spaces/qingxu98/gpt-academic) | After logging in to huggingface, copy [this space](https://huggingface.co/spaces/qingxu98/gpt-academic)
-... | ...
-
+One-click polishing | Supports one-click polishing and one-click searching for grammar errors in papers.
+One-click Chinese-English translation | One-click Chinese-English translation.
+One-click code interpretation | Displays, explains, generates, and adds comments to code.
+[Custom shortcut keys](https://www.bilibili.com/video/BV14s4y1E7jN) | Supports custom shortcut keys.
+Modular design | Supports custom powerful [function plug-ins](https://github.com/binary-husky/chatgpt_academic/tree/master/crazy_functions), plug-ins support [hot update](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97).
+[Self-program profiling](https://www.bilibili.com/video/BV1cj411A7VW) | [Function plug-in] [One-click understanding](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) of the source code of this project
+[Program profiling](https://www.bilibili.com/video/BV1cj411A7VW) | [Function plug-in] One-click profiling of other project trees in Python/C/C++/Java/Lua/...
+Reading papers, [translating](https://www.bilibili.com/video/BV1KT411x7Wn) papers | [Function Plug-in] One-click interpretation of latex/pdf full-text papers and generation of abstracts.
+Latex full-text [translation](https://www.bilibili.com/video/BV1nk4y1Y7Js/), [polishing](https://www.bilibili.com/video/BV1FT411H7c5/) | [Function plug-in] One-click translation or polishing of latex papers.
+Batch annotation generation | [Function plug-in] One-click batch generation of function annotations.
+Markdown [Chinese-English translation](https://www.bilibili.com/video/BV1yo4y157jV/) | [Function plug-in] Have you seen the [README](https://github.com/binary-husky/chatgpt_academic/blob/master/docs/README_EN.md) in the five languages above?
+Chat analysis report generation | [Function plug-in] Automatically generate summary reports after running.
+[PDF full-text translation function](https://www.bilibili.com/video/BV1KT411x7Wn) | [Function plug-in] PDF paper extract title & summary + translate full text (multi-threaded)
+[Arxiv Assistant](https://www.bilibili.com/video/BV1LM4y1279X) | [Function plug-in] Enter the arxiv article url and you can translate abstracts and download PDFs with one click.
+[Google Scholar Integration Assistant](https://www.bilibili.com/video/BV19L411U7ia) | [Function plug-in] Given any Google Scholar search page URL, let GPT help you [write relatedworks](https://www.bilibili.com/video/BV1GP411U7Az/)
+Internet information aggregation+GPT | [Function plug-in] One-click [let GPT get information from the Internet first](https://www.bilibili.com/video/BV1om4y127ck), then answer questions, and let the information never be outdated.
+Formula/image/table display | Can display formulas in both [tex form and render form](https://user-images.githubusercontent.com/96192199/230598842-1d7fcddd-815d-40ee-af60-baf488a199df.png), support formulas and code highlighting.
+Multi-threaded function plug-in support | Supports multi-threaded calling of chatgpt, and can process [massive text](https://www.bilibili.com/video/BV1FT411H7c5/) or programs with one click.
+Start Dark Gradio [theme](https://github.com/binary-husky/chatgpt_academic/issues/173) | Add ```/?__theme=dark``` after the browser URL to switch to the dark theme.
+[Multiple LLM models](https://www.bilibili.com/video/BV1wT411p7yf) support, [API2D](https://api2d.com/) interface support | The feeling of being served by GPT3.5, GPT4, [Tsinghua ChatGLM](https://github.com/THUDM/ChatGLM-6B), and [Fudan MOSS](https://github.com/OpenLMLab/MOSS) at the same time must be great, right?
+More LLM model access, support [huggingface deployment](https://huggingface.co/spaces/qingxu98/gpt-academic) | Add Newbing interface (New Bing), introduce Tsinghua [Jittorllms](https://github.com/Jittor/JittorLLMs) to support [LLaMA](https://github.com/facebookresearch/llama), [RWKV](https://github.com/BlinkDL/ChatRWKV) and [Panguα](https://openi.org.cn/pangu/)
+More new feature displays (image generation, etc.)…… | See the end of this document for more...
-
-- New interface (switch between "left-right layout" and "up-down layout" by modifying the LAYOUT option in config.py)
+- New interface (modify the LAYOUT option in `config.py` to switch between "left and right layout" and "up and down layout")
-
-
-
-- All buttons are dynamically generated by reading functional.py and can add custom functionality at will, freeing up clipboard
+
- All buttons are dynamically generated by reading `functional.py`, and you can add custom functions freely to unleash the power of clipboard.
-- Proofreading / correcting
+- polishing/correction
-- If the output contains formulas, it will be displayed in both the tex form and the rendering form at the same time, which is convenient for copying and reading
+- If the output contains formulas, they will be displayed in both `tex` and render form, making it easy to copy and read.
-- Don't want to read the project code? Just take the whole project to chatgpt
+- Tired of reading the project code? ChatGPT can explain it all.
-- Multiple major language model mixing calls (ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4)
+- Multiple large language models are mixed, such as ChatGLM + OpenAI-GPT3.5 + [API2D](https://api2d.com/)-GPT4.
-Multiple major language model mixing call [huggingface beta version](https://huggingface.co/spaces/qingxu98/academic-chatgpt-beta) (the huggingface version does not support chatglm)
-
-
---
+# Installation
+## Method 1: Directly running (Windows, Linux or MacOS)
-## Installation-Method 1: Run directly (Windows, Linux or MacOS)
-
-1. Download project
+1. Download the project
```sh
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
```
-2. Configure API_KEY and proxy settings
+2. Configure the API_KEY
+Configure the API KEY in `config.py`, [special network environment settings](https://github.com/binary-husky/gpt_academic/issues/1).
-In `config.py`, configure the overseas Proxy and OpenAI API KEY as follows:
-```
-1. If you are in China, you need to set up an overseas proxy to use the OpenAI API smoothly. Please read config.py carefully for setup details (1. Modify USE_PROXY to True; 2. Modify proxies according to the instructions).
-2. Configure the OpenAI API KEY. You need to register and obtain an API KEY on the OpenAI website. Once you get the API KEY, you can configure it in the config.py file.
-3. Issues related to proxy networks (network timeouts, proxy failures) are summarized at https://github.com/binary-husky/chatgpt_academic/issues/1
-```
-(P.S. When the program runs, it will first check whether there is a private configuration file named `config_private.py` and use the same-name configuration in `config.py` to overwrite it. Therefore, if you can understand our configuration reading logic, we strongly recommend that you create a new configuration file named `config_private.py` next to `config.py` and transfer (copy) the configuration in `config.py` to` config_private.py`. `config_private.py` is not controlled by git and can make your privacy information more secure.))
+(P.S. When the program is running, it will first check if there is a private configuration file named `config_private.py` and use the configurations in it to override the same configurations in `config.py`. Therefore, if you can understand our configuration reading logic, we strongly recommend that you create a new configuration file named `config_private.py` next to `config.py` and transfer (copy) the configurations in `config.py` to `config_private.py`. `config_private.py` is not controlled by git and can make your private information more secure. P.S. The project also supports configuring most options through `environment variables`. Please refer to the format of `docker-compose` file when writing. Reading priority: `environment variables` > `config_private.py` > `config.py`)
-3. Install dependencies
+3. Install the dependencies
```sh
-# (Option One) Recommended
-python -m pip install -r requirements.txt
+# (Option I: If familiar with python) (python version 3.9 or above, the newer the better), note: use official pip source or Ali pip source, temporary switching method: python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
+python -m pip install -r requirements.txt
-# (Option Two) If you use anaconda, the steps are similar:
-# (Option Two.1) conda create -n gptac_venv python=3.11
-# (Option Two.2) conda activate gptac_venv
-# (Option Two.3) python -m pip install -r requirements.txt
-
-# Note: Use official pip source or Ali pip source. Other pip sources (such as some university pips) may have problems, and temporary replacement methods are as follows:
-# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
+# (Option II: If not familiar with python) Use anaconda, the steps are similar (https://www.bilibili.com/video/BV1rc411W7Dr):
+conda create -n gptac_venv python=3.11 # create anaconda environment
+conda activate gptac_venv # activate anaconda environment
+python -m pip install -r requirements.txt # this step is the same as pip installation
```
-If you need to support Tsinghua ChatGLM, you need to install more dependencies (if you are not familiar with python or your computer configuration is not good, we recommend not to try):
+
If you need to support Tsinghua ChatGLM/Fudan MOSS as a backend, click to expand
+
+
+[Optional step] If you need to support Tsinghua ChatGLM/Fudan MOSS as a backend, you need to install more dependencies (prerequisites: familiar with Python + used Pytorch + computer configuration is strong enough):
```sh
-python -m pip install -r request_llm/requirements_chatglm.txt
+# [Optional Step I] Support Tsinghua ChatGLM. Tsinghua ChatGLM remarks: if you encounter the "Call ChatGLM fail cannot load ChatGLM parameters" error, refer to this: 1: The default installation above is torch + cpu version, to use cuda, you need to uninstall torch and reinstall torch + cuda; 2: If the model cannot be loaded due to insufficient local configuration, you can modify the model accuracy in request_llm/bridge_chatglm.py, and change AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) to AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code = True)
+python -m pip install -r request_llm/requirements_chatglm.txt
+
+# [Optional Step II] Support Fudan MOSS
+python -m pip install -r request_llm/requirements_moss.txt
+git clone https://github.com/OpenLMLab/MOSS.git request_llm/moss # When executing this line of code, you must be in the root directory of the project
+
+# [Optional Step III] Make sure the AVAIL_LLM_MODELS in the config.py configuration file includes the expected models. Currently supported models are as follows (the jittorllms series only supports the docker solution for the time being):
+AVAIL_LLM_MODELS = ["gpt-3.5-turbo", "api2d-gpt-3.5-turbo", "gpt-4", "api2d-gpt-4", "chatglm", "newbing", "moss"] # + ["jittorllms_rwkv", "jittorllms_pangualpha", "jittorllms_llama"]
```
-4. Run
+
+
+
+
+
+4. Run it
```sh
python main.py
+```5. Test Function Plugin
```
-
-5. Test function plugins
-```
-- Test Python project analysis
- In the input area, enter `./crazy_functions/test_project/python/dqn`, and then click "Analyze the entire Python project"
-- Test self-code interpretation
- Click "[Multithreading Demo] Interpretation of This Project Itself (Source Code Interpretation)"
-- Test experimental function template function (requires gpt to answer what happened today in history). You can use this function as a template to implement more complex functions.
+- Test function plugin template function (ask GPT what happened today in history), based on which you can implement more complex functions as a template
Click "[Function Plugin Template Demo] Today in History"
-- There are more functions to choose from in the function plugin area drop-down menu.
```
-## Installation-Method 2: Use Docker (Linux)
+## Installation - Method 2: Using Docker
+
+1. ChatGPT Only (Recommended for Most People)
-1. ChatGPT only (recommended for most people)
``` sh
-# download project
-git clone https://github.com/binary-husky/chatgpt_academic.git
-cd chatgpt_academic
-# configure overseas Proxy and OpenAI API KEY
-Edit config.py with any text editor
-# Install
-docker build -t gpt-academic .
-# Run
+git clone https://github.com/binary-husky/chatgpt_academic.git # Download project
+cd chatgpt_academic # Enter path
+nano config.py # Edit config.py with any text editor, configure "Proxy", "API_KEY" and "WEB_PORT" (e.g. 50923), etc.
+docker build -t gpt-academic . # Install
+
+#(Last step - option 1) In a Linux environment, use `--net=host` for convenience and speed.
docker run --rm -it --net=host gpt-academic
+#(Last step - option 2) On macOS/windows environment, only -p option can be used to expose the container's port (e.g. 50923) to the port of the main machine.
+docker run --rm -it -e WEB_PORT=50923 -p 50923:50923 gpt-academic
+```
-# Test function plug-in
-## Test function plugin template function (requires gpt to answer what happened today in history). You can use this function as a template to implement more complex functions.
-Click "[Function Plugin Template Demo] Today in History"
-## Test Abstract Writing for Latex Projects
-Enter ./crazy_functions/test_project/latex/attention in the input area, and then click "Read Tex Paper and Write Abstract"
-## Test Python Project Analysis
-Enter ./crazy_functions/test_project/python/dqn in the input area and click "Analyze the entire Python project."
+2. ChatGPT + ChatGLM + MOSS (Requires Docker Knowledge)
-More functions are available in the function plugin area drop-down menu.
+``` sh
+# Modify docker-compose.yml, delete Plan 1 and Plan 3, and keep Plan 2. Modify the configuration of Plan 2 in docker-compose.yml, refer to the comments in it for configuration.
+docker-compose up
```
-2. ChatGPT+ChatGLM (requires strong familiarity with docker + strong computer configuration)
+3. ChatGPT + LLAMA + Pangu + RWKV (Requires Docker Knowledge)
``` sh
-# Modify dockerfile
-cd docs && nano Dockerfile+ChatGLM
-# How to build | 如何构建 (Dockerfile+ChatGLM在docs路径下,请先cd docs)
-docker build -t gpt-academic --network=host -f Dockerfile+ChatGLM .
-# How to run | 如何运行 (1) 直接运行:
-docker run --rm -it --net=host --gpus=all gpt-academic
-# How to run | 如何运行 (2) 我想运行之前进容器做一些调整:
-docker run --rm -it --net=host --gpus=all gpt-academic bash
+# Modify docker-compose.yml, delete Plan 1 and Plan 2, and keep Plan 3. Modify the configuration of Plan 3 in docker-compose.yml, refer to the comments in it for configuration.
+docker-compose up
```
+## Installation - Method 3: Other Deployment Options
-## Installation-Method 3: Other Deployment Methods
+1. How to Use Reverse Proxy URL/Microsoft Cloud Azure API
+Configure API_URL_REDIRECT according to the instructions in 'config.py'.
-1. Remote Cloud Server Deployment
-Please visit [Deployment Wiki-1] (https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
+2. Deploy to a Remote Server (Requires Knowledge and Experience with Cloud Servers)
+Please visit [Deployment Wiki-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
-2. Use WSL2 (Windows Subsystem for Linux)
+3. Using WSL2 (Windows Subsystem for Linux)
Please visit [Deployment Wiki-2](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BD%BF%E7%94%A8WSL2%EF%BC%88Windows-Subsystem-for-Linux-%E5%AD%90%E7%B3%BB%E7%BB%9F%EF%BC%89%E9%83%A8%E7%BD%B2)
+4. How to Run Under a Subdomain (e.g. `http://localhost/subpath`)
+Please visit [FastAPI Running Instructions](docs/WithFastapi.md)
-## Installation-Proxy Configuration
-### Method 1: Conventional method
-[Configure Proxy](https://github.com/binary-husky/chatgpt_academic/issues/1)
-
-### Method Two: Step-by-step tutorial for newcomers
-[Step-by-step tutorial for newcomers](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BB%A3%E7%90%86%E8%BD%AF%E4%BB%B6%E9%97%AE%E9%A2%98%E7%9A%84%E6%96%B0%E6%89%8B%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%EF%BC%88%E6%96%B9%E6%B3%95%E5%8F%AA%E9%80%82%E7%94%A8%E4%BA%8E%E6%96%B0%E6%89%8B%EF%BC%89)
+5. Using docker-compose to Run
+Read the docker-compose.yml and follow the prompts.
---
+# Advanced Usage
+## Custom New Shortcut Buttons / Custom Function Plugins
-## Customizing Convenient Buttons (Customizing Academic Shortcuts)
-Open `core_functional.py` with any text editor and add an item as follows, then restart the program (if the button has been successfully added and visible, both the prefix and suffix support hot modification without the need to restart the program to take effect). For example:
+1. Custom New Shortcut Buttons (Academic Hotkey)
+Open `core_functional.py` with any text editor, add an entry as follows and restart the program. (If the button has been successfully added and is visible, the prefix and suffix can be hot-modified without having to restart the program.)
+For example,
```
-"Super English to Chinese translation": {
- # Prefix, which will be added before your input. For example, to describe your requirements, such as translation, code interpretation, polishing, etc.
- "Prefix": "Please translate the following content into Chinese and use a markdown table to interpret the proprietary terms in the text one by one:\n\n",
-
- # Suffix, which will be added after your input. For example, combined with the prefix, you can put your input content in quotes.
+"Super English-to-Chinese": {
+ # Prefix, which will be added before your input. For example, used to describe your requests, such as translation, code explanation, polishing, etc.
+ "Prefix": "Please translate the following content into Chinese and then use a markdown table to explain the proprietary terms that appear in the text:\n\n",
+
+ # Suffix, which is added after your input. For example, with the prefix, your input content can be surrounded by quotes.
"Suffix": "",
},
```
@@ -207,85 +198,125 @@ Open `core_functional.py` with any text editor and add an item as follows, then
-Fonctionnalité | Description
+Functionnalité | Description
--- | ---
-Polissage en un clic | Prend en charge la correction en un clic et la recherche d'erreurs de syntaxe dans les documents de recherche.
-Traduction Chinois-Anglais en un clic | Une touche pour traduire la partie chinoise en anglais ou celle anglaise en chinois.
-Explication de code en un clic | Affiche et explique correctement le code.
-[Raccourcis clavier personnalisables](https://www.bilibili.com/video/BV14s4y1E7jN) | Prend en charge les raccourcis clavier personnalisables.
-[Configuration du serveur proxy](https://www.bilibili.com/video/BV1rc411W7Dr) | Prend en charge la configuration du serveur proxy.
-Conception modulaire | Prend en charge la personnalisation des plugins de fonctions et des [plugins] de fonctions hiérarchiques personnalisés, et les plugins prennent en charge [la mise à jour à chaud](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97).
-[Auto-analyse du programme](https://www.bilibili.com/video/BV1cj411A7VW) | [Plugins] [Lire en un clic](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) le code source de ce projet.
-[Analyse de programme](https://www.bilibili.com/video/BV1cj411A7VW) | [Plugins] En un clic, les projets Python/C/C++/Java/Lua/... peuvent être analysés.
-Lire le document de recherche | [Plugins] Lisez le résumé de l'article en latex et générer un résumé.
-Traduction et polissage de l'article complet en LaTeX | [Plugins] Une touche pour traduire ou corriger en LaTeX
-Génération Commentaire de fonction en vrac | [Plugins] Lisez en un clic les fonctions et générez des commentaires de fonction.
-Rapport d'analyse automatique des chats générés | [Plugins] Génère un rapport de synthèse après l'exécution.
-[Assistant arxiv](https://www.bilibili.com/video/BV1LM4y1279X) | [Plugins] Entrez l'url de l'article arxiv pour traduire le résumé + télécharger le PDF en un clic
-[Traduction complète des articles PDF](https://www.bilibili.com/video/BV1KT411x7Wn) | [Plugins] Extraire le titre et le résumé de l'article PDF + Traduire le texte entier (multithread)
-[Aide à la recherche Google Academ](https://www.bilibili.com/video/BV19L411U7ia) | [Plugins] Donnez à GPT l'URL de n'importe quelle page de recherche Google Academ pour vous aider à sélectionner des articles intéressants
-Affichage de formules/images/tableaux | Afficher la forme traduite et rendue d'une formule en même temps, plusieurs formules et surlignage du code prend en charge
-Prise en charge des plugins multithread | Prise en charge de l'appel multithread de chatgpt, traitement en masse de texte ou de programmes en un clic
-Activer le thème Gradio sombre [theme](https://github.com/binary-husky/chatgpt_academic/issues/173) au démarrage | Ajoutez ```/?__dark-theme=true``` à l'URL du navigateur pour basculer vers le thème sombre
-[Prise en charge de plusieurs modèles LLM](https://www.bilibili.com/video/BV1wT411p7yf), [prise en charge de l'interface API2D](https://api2d.com/) | Comment cela serait-il de se faire servir par GPT3.5, GPT4 et la [ChatGLM de Tsinghua](https://github.com/THUDM/ChatGLM-6B) en même temps?
-Expérience en ligne d'huggingface sans science | Après vous être connecté à huggingface, copiez [cet espace](https://huggingface.co/spaces/qingxu98/gpt-academic)
-... | ...
+Révision en un clic | prend en charge la révision en un clic et la recherche d'erreurs de syntaxe dans les articles
+Traduction chinois-anglais en un clic | Traduction chinois-anglais en un clic
+Explication de code en un clic | Affichage, explication, génération et ajout de commentaires de code
+[Raccourcis personnalisés](https://www.bilibili.com/video/BV14s4y1E7jN) | prend en charge les raccourcis personnalisés
+Conception modulaire | prend en charge de puissants plugins de fonction personnalisée, les plugins prennent en charge la [mise à jour à chaud](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)
+[Autoscanner](https://www.bilibili.com/video/BV1cj411A7VW) | [Plug-in de fonction] [Compréhension instantanée](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) du code source de ce projet
+[Analyse de programme](https://www.bilibili.com/video/BV1cj411A7VW) | [Plug-in de fonction] Analyse en un clic de la structure d'autres projets Python / C / C ++ / Java / Lua / ...
+Lecture d'articles, [traduction](https://www.bilibili.com/video/BV1KT411x7Wn) d'articles | [Plug-in de fonction] Compréhension instantanée de l'article latex / pdf complet et génération de résumés
+[Traduction](https://www.bilibili.com/video/BV1nk4y1Y7Js/) et [révision](https://www.bilibili.com/video/BV1FT411H7c5/) complets en latex | [Plug-in de fonction] traduction ou révision en un clic d'articles en latex
+Génération de commentaires en masse | [Plug-in de fonction] Génération en un clic de commentaires de fonction en masse
+Traduction [chinois-anglais](https://www.bilibili.com/video/BV1yo4y157jV/) en Markdown | [Plug-in de fonction] avez-vous vu la [README](https://github.com/binary-husky/chatgpt_academic/blob/master/docs/README_EN.md) pour les 5 langues ci-dessus?
+Génération de rapports d'analyse de chat | [Plug-in de fonction] Génère automatiquement un rapport de résumé après l'exécution
+[Traduction intégrale en pdf](https://www.bilibili.com/video/BV1KT411x7Wn) | [Plug-in de fonction] Extraction de titre et de résumé de l'article pdf + traduction intégrale (multi-thread)
+[Aide à arxiv](https://www.bilibili.com/video/BV1LM4y1279X) | [Plug-in de fonction] Entrer l'url de l'article arxiv pour traduire et télécharger le résumé en un clic
+[Aide à la recherche Google Scholar](https://www.bilibili.com/video/BV19L411U7ia) | [Plug-in de fonction] Donnez l'URL de la page de recherche Google Scholar, laissez GPT vous aider à [écrire des ouvrages connexes](https://www.bilibili.com/video/BV1GP411U7Az/)
+Aggrégation d'informations en ligne et GPT | [Plug-in de fonction] Permet à GPT de [récupérer des informations en ligne](https://www.bilibili.com/video/BV1om4y127ck), puis de répondre aux questions, afin que les informations ne soient jamais obsolètes
+Affichage d'équations / images / tableaux | Fournit un affichage simultané de [la forme tex et de la forme rendue](https://user-images.githubusercontent.com/96192199/230598842-1d7fcddd-815d-40ee-af60-baf488a199df.png), prend en charge les formules mathématiques et la coloration syntaxique du code
+Prise en charge des plugins à plusieurs threads | prend en charge l'appel multithread de chatgpt, un clic pour traiter [un grand nombre d'articles](https://www.bilibili.com/video/BV1FT411H7c5/) ou de programmes
+Thème gradio sombre en option de démarrage | Ajoutez```/?__theme=dark``` à la fin de l'URL du navigateur pour basculer vers le thème sombre
+[Prise en charge de plusieurs modèles LLM](https://www.bilibili.com/video/BV1wT411p7yf), [API2D](https://api2d.com/) | Sera probablement très agréable d'être servi simultanément par GPT3.5, GPT4, [ChatGLM de Tsinghua](https://github.com/THUDM/ChatGLM-6B), [MOSS de Fudan](https://github.com/OpenLMLab/MOSS)
+Plus de modèles LLM, déploiement de [huggingface](https://huggingface.co/spaces/qingxu98/gpt-academic) | Ajout prise en charge de l'interface Newbing (nouvelle bing), introduction du support de [Jittorllms de Tsinghua](https://github.com/Jittor/JittorLLMs), [LLaMA](https://github.com/facebookresearch/llama), [RWKV](https://github.com/BlinkDL/ChatRWKV) et [Panguα](https://openi.org.cn/pangu/)
+Plus de nouvelles fonctionnalités (génération d'images, etc.) ... | Voir la fin de ce document pour plus de détails ...
-Vous êtes un traducteur professionnel d'articles universitaires en français.
-
-Ceci est un fichier Markdown, veuillez le traduire en français sans modifier les commandes Markdown existantes :
-
-- Nouvelle interface (modifiable en modifiant l'option de mise en page dans config.py pour basculer entre les mises en page gauche-droite et haut-bas)
+- Nouvelle interface (modifier l'option LAYOUT de `config.py` pour passer d'une disposition ``gauche-droite`` à une disposition ``haut-bas``)
-
+
機能 | 説明
--- | ---
-ワンクリック整形 | 論文の文法エラーを一括で正確に修正できます。
-ワンクリック日英翻訳 | 日英翻訳には、ワンクリックで対応できます。
-ワンクリックコード説明 | コードの正しい表示と説明が可能です。
-[カスタムショートカットキー](https://www.bilibili.com/video/BV14s4y1E7jN) | カスタムショートカットキーをサポートします。
-[プロキシサーバーの設定](https://www.bilibili.com/video/BV1rc411W7Dr) | プロキシサーバーの設定をサポートします。
-モジュラーデザイン | カスタム高階関数プラグインと[関数プラグイン]、プラグイン[ホット更新]のサポートが可能です。詳細は[こちら](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)
-[自己プログラム解析](https://www.bilibili.com/video/BV1cj411A7VW) | [関数プラグイン][ワンクリック理解](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A)このプロジェクトのソースコード
-[プログラム解析機能](https://www.bilibili.com/video/BV1cj411A7VW) | [関数プラグイン] ワンクリックで別のPython/C/C++/Java/Lua/...プロジェクトツリーを解析できます。
-論文読解 | [関数プラグイン] LaTeX論文の全文をワンクリックで解読し、要約を生成します。
-LaTeX全文翻訳、整形 | [関数プラグイン] ワンクリックでLaTeX論文を翻訳または整形できます。
-注釈生成 | [関数プラグイン] ワンクリックで関数の注釈を大量に生成できます。
-チャット分析レポート生成 | [関数プラグイン] 実行後、まとめレポートを自動生成します。
-[arxivヘルパー](https://www.bilibili.com/video/BV1LM4y1279X) | [関数プラグイン] 入力したarxivの記事URLで要約をワンクリック翻訳+PDFダウンロードができます。
-[PDF論文全文翻訳機能](https://www.bilibili.com/video/BV1KT411x7Wn) | [関数プラグイン] PDF論文タイトルと要約を抽出し、全文を翻訳します(マルチスレッド)。
-[Google Scholar Integratorヘルパー](https://www.bilibili.com/video/BV19L411U7ia) | [関数プラグイン] 任意のGoogle Scholar検索ページURLを指定すると、gptが興味深い記事を選択します。
-数式/画像/テーブル表示 | 数式のTex形式とレンダリング形式を同時に表示できます。数式、コードのハイライトをサポートしています。
-マルチスレッド関数プラグインサポート | ChatGPTをマルチスレッドで呼び出すことができ、大量のテキストやプログラムを簡単に処理できます。
-ダークグラジオ[テーマ](https://github.com/binary-husky/chatgpt_academic/issues/173)の起動 | 「/?__dark-theme=true」というURLをブラウザに追加することで、ダークテーマに切り替えることができます。
-[多数のLLMモデル](https://www.bilibili.com/video/BV1wT411p7yf)をサポート、[API2D](https://api2d.com/)インターフェースをサポート | GPT3.5、GPT4、[清華ChatGLM](https://github.com/THUDM/ChatGLM-6B)による同時サポートは、とても素晴らしいですね!
-huggingface免科学上网[オンライン版](https://huggingface.co/spaces/qingxu98/gpt-academic) | huggingfaceにログイン後、[このスペース](https://huggingface.co/spaces/qingxu98/gpt-academic)をコピーしてください。
-...... | ......
-
-
+一键校正 | 一键で校正可能、論文の文法エラーを検索することができる
+一键中英翻訳 | 一键で中英翻訳可能
+一键コード解説 | コードを表示し、解説し、生成し、コードに注釈をつけることができる
+[自分でカスタマイズ可能なショートカットキー](https://www.bilibili.com/video/BV14s4y1E7jN) | 自分でカスタマイズ可能なショートカットキーをサポートする
+モジュール化された設計 | カスタマイズ可能な[強力な関数プラグイン](https://github.com/binary-husky/chatgpt_academic/tree/master/crazy_functions)をサポートし、プラグインは[ホットアップデート](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)に対応している
+[自己プログラム解析](https://www.bilibili.com/video/BV1cj411A7VW) | [関数プラグイン] [一键読解](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A)このプロジェクトのソースコード
+プログラム解析 | [関数プラグイン] 一鍵で他のPython/C/C++/Java/Lua/...プロジェクトを分析できる
+論文の読み、[翻訳](https://www.bilibili.com/video/BV1KT411x7Wn) | [関数プラグイン] LaTex/ PDF論文の全文を一鍵で読み解き、要約を生成することができる
+LaTex全文[翻訳](https://www.bilibili.com/video/BV1nk4y1Y7Js/)、[校正](https://www.bilibili.com/video/BV1FT411H7c5/) | [関数プラグイン] LaTex論文の翻訳または校正を一鍵で行うことができる
+一括で注釈を生成 | [関数プラグイン] 一鍵で関数に注釈をつけることができる
+Markdown[中英翻訳](https://www.bilibili.com/video/BV1yo4y157jV/) | [関数プラグイン] 上記の5種類の言語の[README](https://github.com/binary-husky/chatgpt_academic/blob/master/docs/README_EN.md)を見たことがありますか?
+チャット分析レポート生成 | [関数プラグイン] 実行後、自動的に概要報告書を生成する
+[PDF論文全文翻訳機能](https://www.bilibili.com/video/BV1KT411x7Wn) | [関数プラグイン] PDF論文からタイトルと要約を抽出し、全文を翻訳する(マルチスレッド)
+[Arxivアシスタント](https://www.bilibili.com/video/BV1LM4y1279X) | [関数プラグイン] arxiv記事のURLを入力するだけで、要約を一鍵翻訳し、PDFをダウンロードできる
+[Google Scholar 総合アシスタント](https://www.bilibili.com/video/BV19L411U7ia) | [関数プラグイン] 任意のGoogle Scholar検索ページURLを指定すると、gptが[related works](https://www.bilibili.com/video/BV1GP411U7Az/)を作成する
+インターネット情報収集+GPT | [関数プラグイン] まずGPTに[インターネットから情報を収集](https://www.bilibili.com/video/BV1om4y127ck)してから質問に回答させ、情報が常に最新であるようにする
+数式/画像/表表示 | 数式の[tex形式とレンダリング形式](https://user-images.githubusercontent.com/96192199/230598842-1d7fcddd-815d-40ee-af60-baf488a199df.png)を同時に表示し、数式、コードハイライトをサポートしている
+マルチスレッド関数プラグインがサポートされている | chatgptをマルチスレッドで呼び出し、[大量のテキスト](https://www.bilibili.com/video/BV1FT411H7c5/)またはプログラムを一鍵で処理できる
+ダークグラジオ[テーマの起動](https://github.com/binary-husky/chatgpt_academic/issues/173) | ブラウザのURLの後ろに```/?__theme=dark```を追加すると、ダークテーマを切り替えることができます。
+[多数のLLMモデル](https://www.bilibili.com/video/BV1wT411p7yf)がサポートされ、[API2D](https://api2d.com/)がサポートされている | 同時にGPT3.5、GPT4、[清華ChatGLM](https://github.com/THUDM/ChatGLM-6B)、[復旦MOSS](https://github.com/OpenLMLab/MOSS)に対応
+より多くのLLMモデルが接続され、[huggingfaceデプロイ](https://huggingface.co/spaces/qingxu98/gpt-academic)がサポートされている | Newbingインターフェイス(Newbing)、清華大学の[Jittorllm](https://github.com/Jittor/JittorLLMs)のサポート[LLaMA](https://github.com/facebookresearch/llama), [RWKV](https://github.com/BlinkDL/ChatRWKV)と[盘古α](https://openi.org.cn/pangu/)
+さらに多くの新機能(画像生成など)を紹介する... | この文書の最後に示す...
-
-- 新しいインターフェース(config.pyのLAYOUTオプションを変更するだけで、「左右レイアウト」と「上下レイアウト」を切り替えることができます)
+- 新しいインターフェース(`config.py`のLAYOUTオプションを変更することで、「左右配置」と「上下配置」を切り替えることができます)
-
-Функция | Описание
---- | ---
-Редактирование одним кликом | Поддержка редактирования одним кликом, поиск грамматических ошибок в академических статьях
-Переключение языков "Английский-Китайский" одним кликом | Одним кликом переключайте языки "Английский-Китайский"
-Разъяснение программного кода одним кликом | Вы можете правильно отобразить и объяснить программный код.
-[Настраиваемые сочетания клавиш](https://www.bilibili.com/video/BV14s4y1E7jN) | Поддержка настраиваемых сочетаний клавиш
-[Настройка сервера-прокси](https://www.bilibili.com/video/BV1rc411W7Dr) | Поддержка настройки сервера-прокси
-Модульный дизайн | Поддержка настраиваемых функциональных плагинов высших порядков и функциональных плагинов, поддерживающих [горячее обновление](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)
-[Автоанализ программы](https://www.bilibili.com/video/BV1cj411A7VW) | [Функциональный плагин] [Прочтение в один клик](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A) кода программы проекта
-[Анализ программы](https://www.bilibili.com/video/BV1cj411A7VW) | [Функциональный плагин] Один клик для проанализирования дерева других проектов Python/C/C++/Java/Lua/...
-Чтение статей| [Функциональный плагин] Одним кликом прочитайте весь латех (LaTex) текст статьи и сгенерируйте краткое описание
-Перевод и редактирование всех статей из LaTex | [Функциональный плагин] Перевод или редактирование LaTex-статьи всего одним нажатием кнопки
-Генерация комментариев в пакетном режиме | [Функциональный плагин] Одним кликом сгенерируйте комментарии к функциям в пакетном режиме
-Генерация отчетов пакета CHAT | [Функциональный плагин] Автоматически создавайте сводные отчеты после выполнения
-[Помощник по arxiv](https://www.bilibili.com/video/BV1LM4y1279X) | [Функциональный плагин] Введите URL статьи arxiv, чтобы легко перевести резюме и загрузить PDF-файл
-[Перевод полного текста статьи в формате PDF](https://www.bilibili.com/video/BV1KT411x7Wn) | [Функциональный плагин] Извлеките заголовок статьи, резюме и переведите весь текст статьи (многопоточно)
-[Помощник интеграции Google Scholar](https://www.bilibili.com/video/BV19L411U7ia) | [Функциональный плагин] Дайте GPT выбрать для вас интересные статьи на любой странице поиска Google Scholar.
-Отображение формул/изображений/таблиц | Одновременно отображается tex-форма и рендер-форма формул, поддержка формул, высокоскоростных кодов
-Поддержка функциональных плагинов многопоточности | Поддержка многопоточной работы с плагинами, обрабатывайте огромные объемы текста или программы одним кликом
-Запуск темной темы gradio[подробнее](https://github.com/binary-husky/chatgpt_academic/issues/173) | Добавьте / ?__dark-theme=true в конец URL браузера, чтобы переключиться на темную тему.
-[Поддержка нескольких моделей LLM](https://www.bilibili.com/video/BV1wT411p7yf), поддержка API2D | Находиться между GPT3.5, GPT4 и [清华ChatGLM](https://github.com/THUDM/ChatGLM-6B) должно быть очень приятно, не так ли?
-Альтернатива huggingface без использования научной сети [Онлайн-эксперимент](https://huggingface.co/spaces/qingxu98/gpt-academic) | Войдите в систему, скопируйте пространство [этот пространственный URL](https://huggingface.co/spaces/qingxu98/gpt-academic)
-…… | ……
-
+> При установке зависимостей строго выбирайте версии, **указанные в файле requirements.txt**.
+>
+> `pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/`## Задание
-
-
-- Новый интерфейс (вы можете изменить настройку LAYOUT в config.py, чтобы переключаться между "горизонтальным расположением" и "вертикальным расположением")
- +
+ +
+ +
+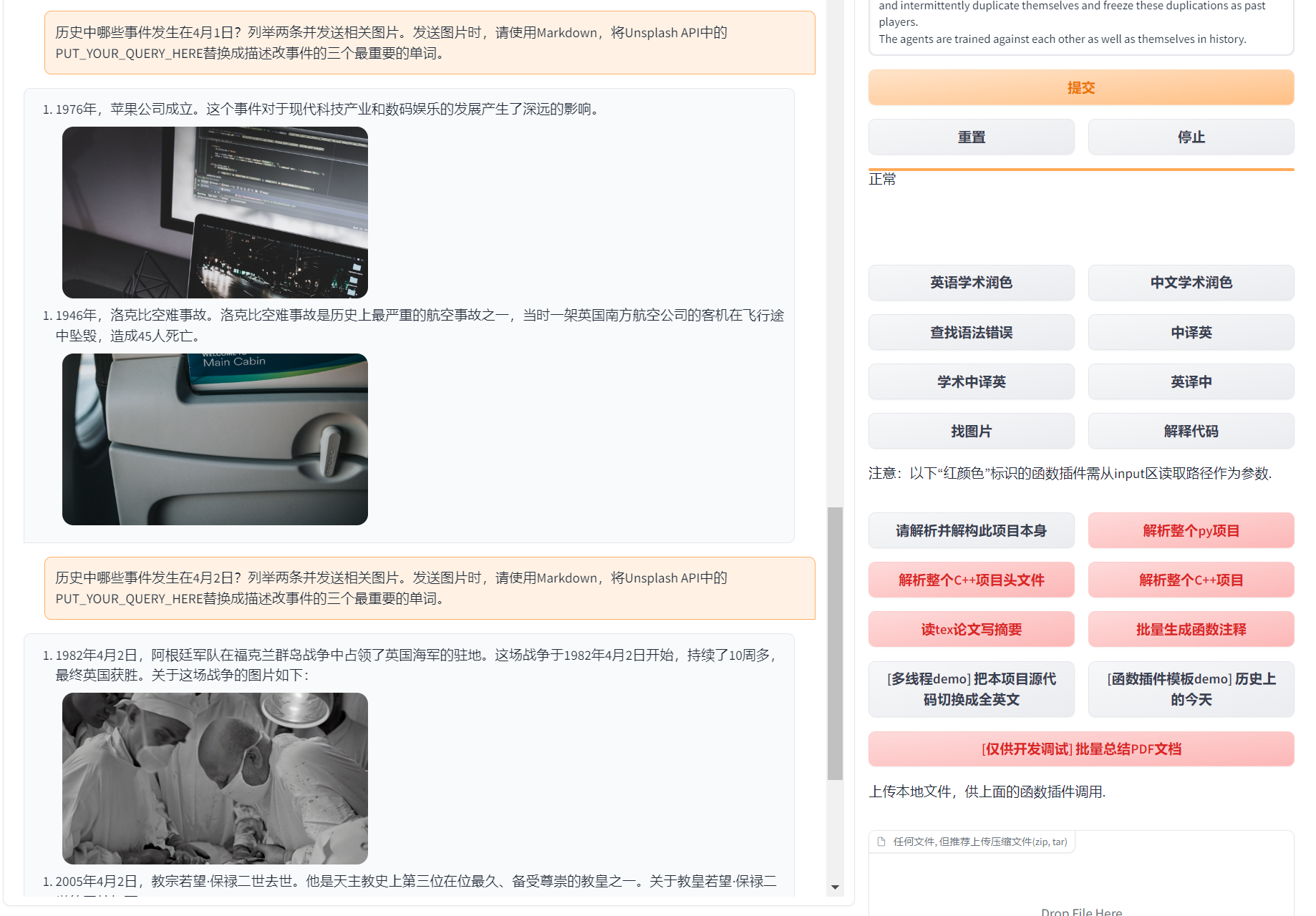 +
+ +
+ +
+ +
+