from helper.text.markdown_reader import read_markdown
class TextHowTo:
htr_tool = """
## Getting Started with the HTR Tool
To quickly run the HTR Tool and transcribe handwritten text, follow these steps:
1. Open the HTR Tool tab.
2. Upload an image or choose an image from the provided Examples (under "Example images to use:" accordin).
Note that the accordin works like a "dropdown" and that you just need to press an example to use it (also, use the pagniation at the bottom to view more examples).
3. The radio button specifes the output file extension, which can be either text or page XML.
4. Click the "Run HTR" button to initiate the HTR process. You can refer to the screenshot below:
Figure - How to Run the HTR Tool
The HTR Tool will transform an image of handwritten text into structured, transcribed text within approximately 1-2 minutes (depending on your hardware).
Note that the generated page XML file is strucutred in such manner that it allows for an easy integration with other software, such as Transkribus.
You can use our own developed Image viewer for the xml output:
"""
reach_out = """ Feel free to reach out if you have any questions or need further assistance!
"""
stepwise_htr_tool = """
## Stepwise HTR Tool
Here you can break down the HTR process into distinct steps: Region segmentation, Line segmentation, Text recognition, and Explore results. You can adjust the settings for each part, and choose from a selection of underlying machine learning models to drive each step of the process. Each step is interconnected, and the output of one step serves as the input for the next step, ensuring a seamless and efficient workflow.
"""
stepwise_htr_tool_tab_intro = """
Follow the instructions below:
"""
htr_tool_api_text = """
## Usage of Client API
If you prefer to run **Fast track** programmatically, we offer an API for that purpose.
- Docuemtnation for gradio client with [python](https://www.gradio.app/guides/getting-started-with-the-python-client)
- Docuemtnation for gradio client with [javascript](https://www.gradio.app/guides/getting-started-with-the-js-client)
**Note**: More extensive APIs and documentation can be added in the future upon request.
See example below for usage of API in python:
"""
stepwise_htr_tool_tab1 = """
### Tab 1: Region Segmentation
The Region Segmentation tab allows you to perform the initial step of segmenting the handwritten text into regions of interest. By adjusting the P-threshold and C-threshold settings, you can control the confidence score required for a prediction and the minimum overlap or similarity for a detected region to be considered valid. Additionally, you can select an underlying machine learning model for region segmentation.
To perform region segmentation, follow these steps:
1. Open the "Region Segmentation" tab.
2. Upload an image or choose an image from the provided Examples (under "Example images to use:" accordin).
3. Configure the region segmentation settings:
- Adjust the P-threshold: Filter and determine the confidence score required for a prediction score to be considered.
- Adjust the C-threshold: Set the minimum required overlap or similarity for a detected region or object to be considered valid.
- Select an underlying machine learning model.
4. Click the "Run Region Segmentation" button to initiate the region segmentation process.
"""
stepwise_htr_tool_tab2 = """
### Tab 2: Line Segmentation
In the Line Segmentation tab, you can further refine the segmentation process by identifying individual lines of text.
Similar to the Region Segmentation tab, you can adjust the P-threshold and C-threshold settings for line segmentation and choose an appropriate machine learning model.
To perform line segmentation, follow these steps:
1. Open the "Line Segmentation" tab.
2. Choice a segmented region from image gallery, which populated with the results from the previous tab.
3. Configure the line segmentation settings:
- Adjust the P-threshold: Filter and determine the confidence score required for a prediction score to be considered.
- Adjust the C-threshold: Set the minimum required overlap or similarity for a detected region or object to be considered valid.
- Select an underlying machine learning model.
4. Click the "Run Line Segmentation" button to initiate the line segmentation process.
"""
stepwise_htr_tool_tab3 = """
### Tab 3: Transcribe Text
The Transcribe Text tab allows you to convert the segmented text into transcriptions. Here, you can select the desired machine learning model for text transcription.
To transcribe text, follow these steps:
1. Open the "Transcribe Text" tab.
2. The image to transcribe is predefined with the results from the previous tab.
3. Configure the text transcription settings:
- Select an underlying machine learning model.
4. Click the "Run Text Transcription" button to initiate the text transcription process.
"""
stepwise_htr_tool_tab4 = """
### Tab 4: Explore Results
Once the transcription is complete, you can explore the results in the Explore Results tab. This tab provides various features for analyzing and interacting with the transcriptions, allowing you to sort and identify both bad and good predictions.
To explore the HTR results, follow these steps:
1. Open the "Explore Results" tab.
2. Analyze the generated results. The image gallery of cropped text line segments is bi-directional coupled through interaction with the dataframe on the left.
3. Use the provided features, such as the prediction score to sort and interact with the image gallery, identifying both bad and good transcriptions.
"""
stepwise_htr_tool_end = """
As mentioned, please note that each tab in this workflow is dependent on the previous steps, where you progressively work through the process in a step-by-step manner.
"""
both_htr_tool_video = """
##
Alternatively, you can watch the instructional video below, which provides a step-by-step walkthrough of the HTR Tool and some additional features.
"""
figure_htr_api = """
Figure - How to run API through a client in a notebook
"""
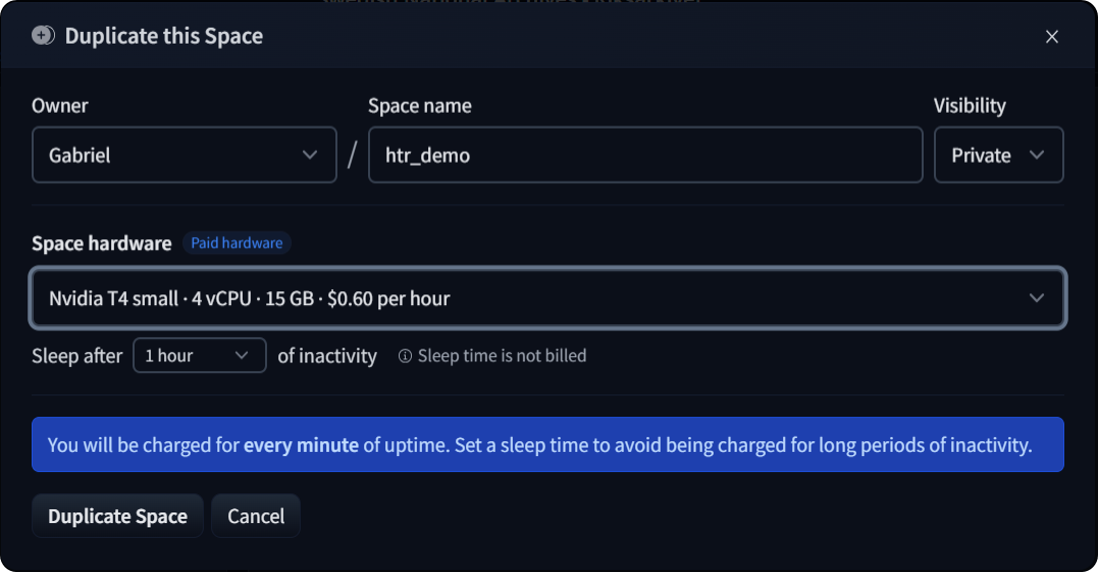
figure_htr_hardware = """
Figure - Choose a hardware that has atleast a GPU
"""
duplicatin_space_htr_text = """
## Duplicating for own use
Please be aware of certain limitations when using the application:
- Primarily, this application is designed for demonstration purposes and is not intended for mass HTR.
- Currently, the Swedish National Archives has constraints on sharing hardware, leading to a queue system for high demand.
- The demo is hosted on Hugging Face domains, and they may rate-limit you if there's an excessive number of requests in a short timeframe, especially when using the API.
For those requiring heavy usage, you can conveniently duplicate the application.
- Duplicate [application](https://huggingface.co/spaces/Riksarkivet/htr_demo?duplicate=true).
By doing so, you'll create your own private app, which allows for unlimited requests without any restrictions. The image below shows the minimum hardware you need to use if you don't have access to hardware youself:
"""
duplicatin_for_privat = """
For individuals with access to dedicated hardware, additional options are available. You have the flexibility to run this application on your own machine utilizing Docker, or by cloning the repository directly. Doing so allows you to leverage your hardware's capabilities to their fullest extent.
- [Clone with Docker](https://huggingface.co/spaces/Riksarkivet/htr_demo?docker=true)
- [Clone Repo](https://huggingface.co/spaces/Riksarkivet/htr_demo/settings?clone=true)
**Note**: To take advantage of CUDA for accelerated inferences, an Nvidia graphics card is required. This setup significantly enhances the performance, ensuring a smoother and faster operation.
"""
code_for_api = """
from gradio_client import Client # pip install gradio_client
# Change url to your client (localhost: http://127.0.0.1:7860/)
client = Client("https://huggingface.co/spaces/Riksarkivet/htr_demo")
job = client.submit(
"https://your.image.url.or.pah.jpg",
api_name="/predict",
)
print(job.result())
"""
output_code_for_api_text = """
### Output from the api
The output from the api is currently in the format of Page XML, which can be imported into this [viewer](https://huggingface.co/spaces/Riksarkivet/Viewer_demo).
"""
output_code_for_api = """
Loaded as API: http://127.0.0.1:7860/ ✔
Swedish National Archives2023-08-21, 13:28:06År 1865.
......................................
# Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
"""
text_faq = read_markdown("helper/text/help/faq_discussion/faq.md")
text_contact = """
"""
text_discussion = read_markdown("helper/text/help/faq_discussion/discussion.md")
if __name__ == "__main__":
pass