---
language:
- en
- ko
pipeline_tag: text-generation
inference: false
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
- llama-2-ko
- llama-pro-ko
---
# LLaMA-Pro-Ko-8B Model Card
### Model Description
LLaMA-Pro is an advanced iteration of the original LLaMA model, augmented with additional Transformer blocks. Unlike its predecessor, Llama-pro, which was specialized for programming and mathematics, Llama-Pro-Ko is tailored to the language domain, undergoing post-training for enhanced performance.
## Development and Training
The NLP & AI Lab at Korea University developed LLaMA-Pro-Ko, a model boasting 8 billion parameters. This model extends LLaMA2-7B by incorporating Korean tokens via vocabulary extension and was further refined by training on a Korean corpus of 10 billion tokens, exclusively without the inclusion of English data.
### Language Specialization and Transfer
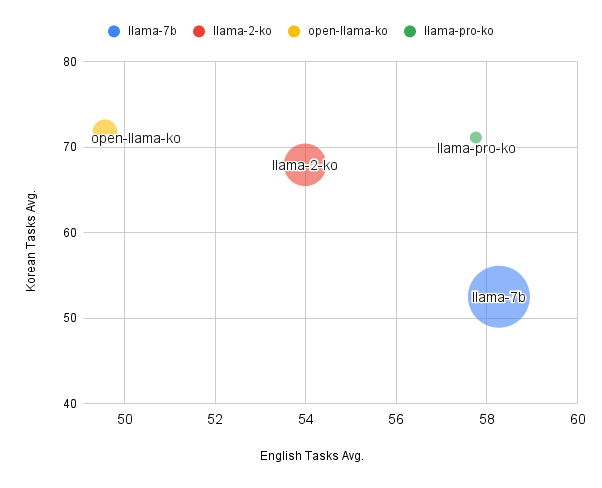
While previous models like Llama-ko and Llama-2-ko experienced diminished English capabilities as they learned Korean, Llama-Pro's language transfer approach aims to bolster Korean language performance with minimal impact on its English proficiency.
### Bilingual Performance Evaluation
LLaMA-Pro-Ko's performance is evaluated on two fronts: its proficiency in English and its mastery of Korean, showcasing its capabilities as a bilingual model.
### Korean Evaluation
#### KoBEST
**5shot**
| | # tokens | copa | HellaSwag | boolq | sentiNeg | AVG |
| ------------------------------------------------------------ | :------: | :-----------: | :-----------: | ------------- | :-----------: | :----------: |
| [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b) | 20B | 0.7626 | 0.4668 | 0.4657 | 0.8295 | 63.11 |
| [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b) | 40B | **0.7927** | 0.4657 | **0.6977** | 0.7611 | 67.93 |
| [beomi/open-llama-2-ko-7b](https://huggingface.co/beomi/open-llama-2-ko-7b) | 15B | 0.7737 | **0.4831** | 0.6824 | **0.8991** | **70.96** |
| llama-pro-ko-8b | 10B | 0.7878 | 0.4748 | 0.6631 | 0.8752 | 70.02 |
**10shot**
| | # tokens | copa | HellaSwag | boolq | sentiNeg | AVG |
| ------------------------------------------------------------ | :------: | :------: | :-------: | :---------: | :---------: | ------------ |
| [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b) | 20B | 0.78 | 0.47 | 0.68 | 0.87 | 70.12 |
| [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b) | 40B | **0.80** | 0.47 | **0.71** | 0.73 | 67.81 |
| [beomi/open-llama-2-ko-7b](https://huggingface.co/beomi/open-llama-2-ko-7b) | 15B | 0.79 | **0.48** | 0.67 | 0.94 | **71.82** |
| llama-pro-ko-8b | 10B | **0.80** | **0.48** | 0.60 | **0.97** | 71.12 |
### English Evaluation
#### Open LLM Benchmark
| | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | AVG | diff |
| :----------------------------------------------------------- | :-------: | :----------: | :-------: | :----------: | :----------: | :----------: | :-------: |
| [meta-llama/Llama-2-7b](https://huggingface.co/meta-llama/Llama-2-7b) | 53.07 | **78.59** | 46.87 | **38.76** | **74.03** | **58.26** | 0 |
| [beomi/llama-2-ko-7b](https://huggingface.co/beomi/llama-2-ko-7b) | 48.46 | 75.28 | 39.56 | 34.49 | 72.14 | 53.99 | -4.28 |
| [beomi/open-llama-2-ko-7b](https://huggingface.co/beomi/open-llama-2-ko-7b) | 46.84 | 69.48 | 29.86 | 35.35 | 66.30 | 49.57 | -8.70 |
| llama-pro-ko-8b | **53.24** | 77.93 | **47.06** | 38.32 | 72.22 | 57.75 | **-0.51** |