LLM Finetuning
With AutoTrain, you can easily finetune large language models (LLMs) on your own data. You can use AutoTrain to finetune LLMs for a variety of tasks, such as text generation, text classification, and text summarization. You can also use AutoTrain to finetune LLMs for specific use cases, such as chatbots, question-answering systems, and code generation and even basic fine-tuning tasks like classic text generation.
Config file task names:
llm: generic trainerllm-sft: SFT trainerllm-reward: Reward trainerllm-dpo: DPO trainerllm-orpo: ORPO trainer
Data Preparation
LLM finetuning accepts data in CSV and JSONL formats. JSONL is the preferred format. How data is formatted depends on the task you are training the LLM for.
Classic Text Generation
For text generation, the data should be in the following format:
| text |
|---|
| wikipedia is a free online encyclopedia |
| it is a collaborative project |
| that anyone can edit |
| wikipedia is the largest and most popular general reference work on the internet |
An example dataset for this format can be found here: stas/openwebtext-10k
Example tasks:
- Text generation
- Code completion
Compatible trainers:
- SFT Trainer
- Generic Trainer
Chatbot / question-answering / code generation / function calling
For this task, you can use CSV or JSONL data. If you are formatting the data yourself (adding start, end tokens, etc.), you can use CSV or JSONL format.
If you do not want to format the data yourself and want --chat-template parameter to format the data for you, you must use JSONL format.
In both cases, CSV and JSONL can be used interchangeably but JSONL is the most preferred format.
To train a chatbot, your data will have content and role. Some models support system role as well.
Here is an example of a chatbot dataset (single sample):
[{'content': 'Help write a letter of 100 -200 words to my future self for '
'Kyra, reflecting on her goals and aspirations.',
'role': 'user'},
{'content': 'Dear Future Self,\n'
'\n'
"I hope you're happy and proud of what you've achieved. As I "
"write this, I'm excited to think about our goals and how far "
"you've come. One goal was to be a machine learning engineer. I "
"hope you've worked hard and become skilled in this field. Keep "
'learning and innovating. Traveling was important to us. I hope '
"you've seen different places and enjoyed the beauty of our "
'world. Remember the memories and lessons. Starting a family '
'mattered to us. If you have kids, treasure every moment. Be '
'patient, loving, and grateful for your family.\n'
'\n'
'Take care of yourself. Rest, reflect, and cherish the time you '
'spend with loved ones. Remember your dreams and celebrate what '
"you've achieved. Your determination brought you here. I'm "
"excited to see the person you've become, the impact you've made, "
'and the love and joy in your life. Embrace opportunities and '
'keep dreaming big.\n'
'\n'
'With love,\n'
'Kyra',
'role': 'assistant'}]As you can see, the data has content and role columns. The role column can be user or assistant or system.
This data is, however, not formatted for training. You can use the --chat-template parameter to format the data during training.
--chat-template supports the following kinds of templates:
none(default)zephyrchatmltokenizer: use chat template mentioned in tokenizer config
A multi-line sample is also shown below:
[{"content": "hello", "role": "user"}, {"content": "hi nice to meet you", "role": "assistant"}]
[{"content": "how are you", "role": "user"}, {"content": "I am fine", "role": "assistant"}]
[{"content": "What is your name?", "role": "user"}, {"content": "My name is Mary", "role": "assistant"}]
[{"content": "Which is the best programming language?", "role": "user"}, {"content": "Python", "role": "assistant"}]
.
.
.An example dataset for this format can be found here: HuggingFaceH4/no_robots
If you dont want to format the data using --chat-template, you can format the data yourself and use the following format:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nHelp write a letter of 100 -200 words to my future self for Kyra, reflecting on her goals and aspirations.<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nDear Future Self,\n\nI hope you're happy and proud of what you've achieved. As I write this, I'm excited to think about our goals and how far you've come. One goal was to be a machine learning engineer. I hope you've worked hard and become skilled in this field. Keep learning and innovating. Traveling was important to us. I hope you've seen different places and enjoyed the beauty of our world. Remember the memories and lessons. Starting a family mattered to us. If you have kids, treasure every moment. Be patient, loving, and grateful for your family.\n\nTake care of yourself. Rest, reflect, and cherish the time you spend with loved ones. Remember your dreams and celebrate what you've achieved. Your determination brought you here. I'm excited to see the person you've become, the impact you've made, and the love and joy in your life. Embrace opportunities and keep dreaming big.\n\nWith love,\nKyra<|eot_id|>A sample multi-line dataset is shown below:
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nhello<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nhi nice to meet you<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nhow are you<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nI am fine<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat is your name?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nMy name is Mary<|eot_id|>"}]
[{"text": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\nToday Date: 03 Oct 2024\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhich is the best programming language?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nPython<|eot_id|>"}]
.
.
.An example dataset for this format can be found here: timdettmers/openassistant-guanaco
In the examples above, we have seen only two turns: one from the user and one from the assistant. However, you can have multiple turns from the user and assistant in a single sample.
Chat models can be trained using the following trainers:
SFT Trainer:
- requires only
textcolumn - example dataset: HuggingFaceH4/no_robots
- requires only
Generic Trainer:
- requires only
textcolumn - example dataset: HuggingFaceH4/no_robots
- requires only
Reward Trainer:
- requires
textandrejected_textcolumns - example dataset: trl-lib/ultrafeedback_binarized
- requires
DPO Trainer:
- requires
prompt,text, andrejected_textcolumns - example dataset: trl-lib/ultrafeedback_binarized
- requires
ORPO Trainer:
- requires
prompt,text, andrejected_textcolumns - example dataset: trl-lib/ultrafeedback_binarized
- requires
The only difference between the data format for reward trainer and DPO/ORPO trainer is that the reward trainer requires only text and rejected_text columns, while the DPO/ORPO trainer requires an additional prompt column.
Training
Local Training
Locally the training can be performed by using autotrain --config config.yaml command. The config.yaml file should contain the following parameters:
task: llm-orpo
base_model: meta-llama/Meta-Llama-3-8B-Instruct
project_name: autotrain-llama3-8b-orpo
log: tensorboard
backend: local
data:
path: argilla/distilabel-capybara-dpo-7k-binarized
train_split: train
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
prompt_text_column: prompt
params:
block_size: 1024
model_max_length: 8192
max_prompt_length: 512
epochs: 3
batch_size: 2
lr: 3e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 4
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: trueIn the above config file, we are training a model using the ORPO trainer.
The model is trained on the meta-llama/Meta-Llama-3-8B-Instruct model.
The data is argilla/distilabel-capybara-dpo-7k-binarized dataset. The chat_template parameter is set to chatml.
The column_mapping parameter is used to map the columns in the dataset to the required columns for the ORPO trainer.
The params section contains the training parameters such as block_size, model_max_length, epochs, batch_size, lr, peft, quantization, target_modules, padding, optimizer, scheduler, gradient_accumulation, and mixed_precision.
The hub section contains the username and token for the Hugging Face account and the push_to_hub parameter is set to true to push the trained model to the Hugging Face Hub.
If you have training file locally, you can change data part to:
data:
path: path/to/training/file
train_split: train # name of the training file
valid_split: null
chat_template: chatml
column_mapping:
text_column: chosen
rejected_text_column: rejected
prompt_text_column: promptThe above assumes you have train.csv or train.jsonl in the path/to/training/file directory and you will be applying chatml template to the data.
You can run the training using the following command:
$ autotrain --config config.yaml
More example config files for finetuning different types of lllm and different tasks can be found in the here.
Training in Hugging Face Spaces
If you are training in Hugging Face Spaces, everything is the same as local training:
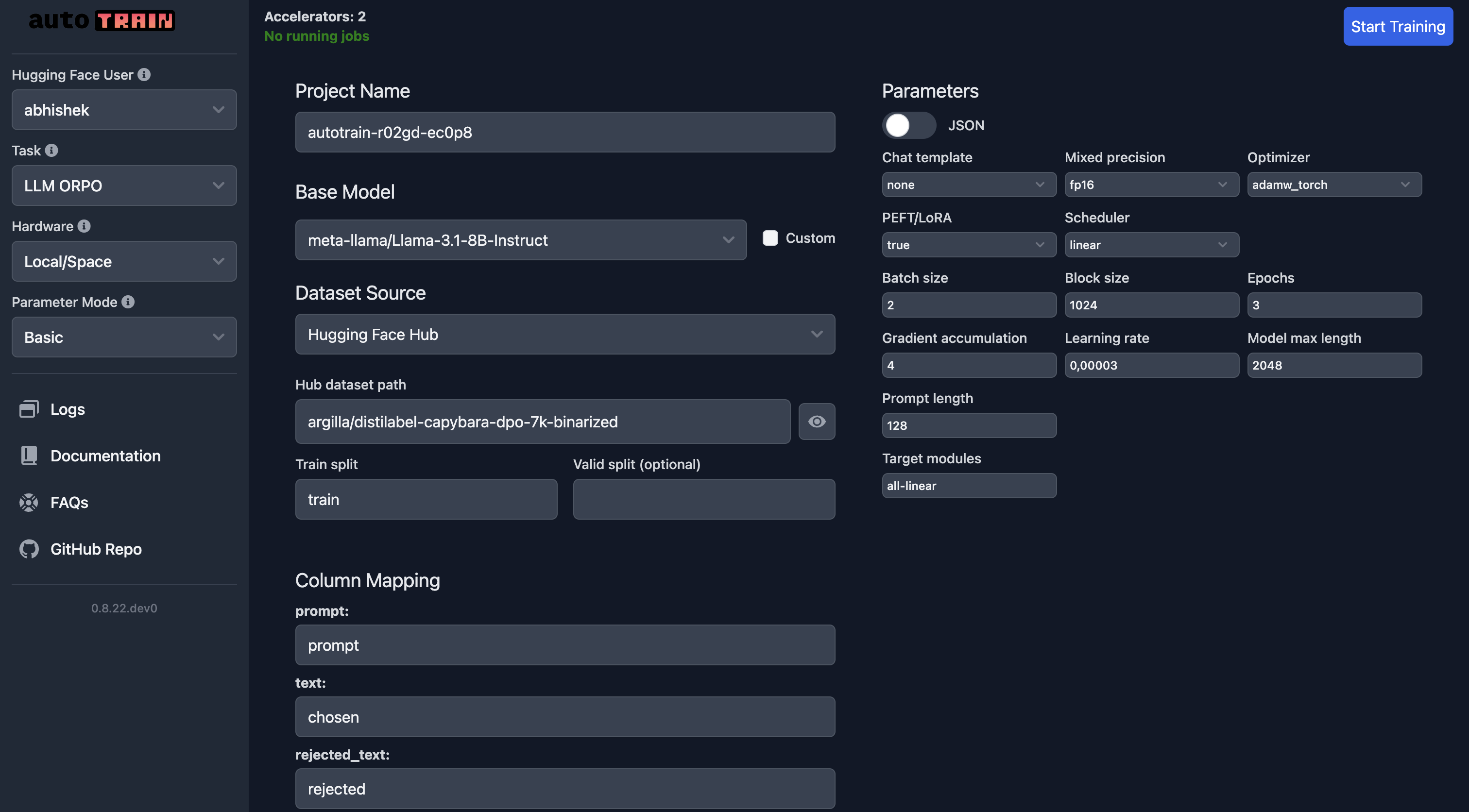
In the UI, you need to make sure you select the right model, the dataset and the splits. Special care should be taken for column_mapping.
Once you are happy with the parameters, you can click on the Start Training button to start the training process.
Parameters
LLM Fine Tuning Parameters
class autotrain.trainers.clm.params.LLMTrainingParams
< source >( model: str = 'gpt2' project_name: str = 'project-name' data_path: str = 'data' train_split: str = 'train' valid_split: Optional = None add_eos_token: bool = True block_size: Union = -1 model_max_length: int = 2048 padding: Optional = 'right' trainer: str = 'default' use_flash_attention_2: bool = False log: str = 'none' disable_gradient_checkpointing: bool = False logging_steps: int = -1 eval_strategy: str = 'epoch' save_total_limit: int = 1 auto_find_batch_size: bool = False mixed_precision: Optional = None lr: float = 3e-05 epochs: int = 1 batch_size: int = 2 warmup_ratio: float = 0.1 gradient_accumulation: int = 4 optimizer: str = 'adamw_torch' scheduler: str = 'linear' weight_decay: float = 0.0 max_grad_norm: float = 1.0 seed: int = 42 chat_template: Optional = None quantization: Optional = 'int4' target_modules: Optional = 'all-linear' merge_adapter: bool = False peft: bool = False lora_r: int = 16 lora_alpha: int = 32 lora_dropout: float = 0.05 model_ref: Optional = None dpo_beta: float = 0.1 max_prompt_length: int = 128 max_completion_length: Optional = None prompt_text_column: Optional = None text_column: str = 'text' rejected_text_column: Optional = None push_to_hub: bool = False username: Optional = None token: Optional = None unsloth: bool = False distributed_backend: Optional = None )
Parameters
- model (str) — Model name to be used for training. Default is “gpt2”.
- project_name (str) — Name of the project and output directory. Default is “project-name”.
- data_path (str) — Path to the dataset. Default is “data”.
- train_split (str) — Configuration for the training data split. Default is “train”.
- valid_split (Optional[str]) — Configuration for the validation data split. Default is None.
- add_eos_token (bool) — Whether to add an EOS token at the end of sequences. Default is True.
- block_size (Union[int, List[int]]) — Size of the blocks for training, can be a single integer or a list of integers. Default is -1.
- model_max_length (int) — Maximum length of the model input. Default is 2048.
- padding (Optional[str]) — Side on which to pad sequences (left or right). Default is “right”.
- trainer (str) — Type of trainer to use. Default is “default”.
- use_flash_attention_2 (bool) — Whether to use flash attention version 2. Default is False.
- log (str) — Logging method for experiment tracking. Default is “none”.
- disable_gradient_checkpointing (bool) — Whether to disable gradient checkpointing. Default is False.
- logging_steps (int) — Number of steps between logging events. Default is -1.
- eval_strategy (str) — Strategy for evaluation (e.g., ‘epoch’). Default is “epoch”.
- save_total_limit (int) — Maximum number of checkpoints to keep. Default is 1.
- auto_find_batch_size (bool) — Whether to automatically find the optimal batch size. Default is False.
- mixed_precision (Optional[str]) — Type of mixed precision to use (e.g., ‘fp16’, ‘bf16’, or None). Default is None.
- lr (float) — Learning rate for training. Default is 3e-5.
- epochs (int) — Number of training epochs. Default is 1.
- batch_size (int) — Batch size for training. Default is 2.
- warmup_ratio (float) — Proportion of training to perform learning rate warmup. Default is 0.1.
- gradient_accumulation (int) — Number of steps to accumulate gradients before updating. Default is 4.
- optimizer (str) — Optimizer to use for training. Default is “adamw_torch”.
- scheduler (str) — Learning rate scheduler to use. Default is “linear”.
- weight_decay (float) — Weight decay to apply to the optimizer. Default is 0.0.
- max_grad_norm (float) — Maximum norm for gradient clipping. Default is 1.0.
- seed (int) — Random seed for reproducibility. Default is 42.
- chat_template (Optional[str]) — Template for chat-based models, options include: None, zephyr, chatml, or tokenizer. Default is None.
- quantization (Optional[str]) — Quantization method to use (e.g., ‘int4’, ‘int8’, or None). Default is “int4”.
- target_modules (Optional[str]) — Target modules for quantization or fine-tuning. Default is “all-linear”.
- merge_adapter (bool) — Whether to merge the adapter layers. Default is False.
- peft (bool) — Whether to use Parameter-Efficient Fine-Tuning (PEFT). Default is False.
- lora_r (int) — Rank of the LoRA matrices. Default is 16.
- lora_alpha (int) — Alpha parameter for LoRA. Default is 32.
- lora_dropout (float) — Dropout rate for LoRA. Default is 0.05.
- model_ref (Optional[str]) — Reference model for DPO trainer. Default is None.
- dpo_beta (float) — Beta parameter for DPO trainer. Default is 0.1.
- max_prompt_length (int) — Maximum length of the prompt. Default is 128.
- max_completion_length (Optional[int]) — Maximum length of the completion. Default is None.
- prompt_text_column (Optional[str]) — Column name for the prompt text. Default is None.
- text_column (str) — Column name for the text data. Default is “text”.
- rejected_text_column (Optional[str]) — Column name for the rejected text data. Default is None.
- push_to_hub (bool) — Whether to push the model to the Hugging Face Hub. Default is False.
- username (Optional[str]) — Hugging Face username for authentication. Default is None.
- token (Optional[str]) — Hugging Face token for authentication. Default is None.
- unsloth (bool) — Whether to use the unsloth library. Default is False.
- distributed_backend (Optional[str]) — Backend to use for distributed training. Default is None.
LLMTrainingParams: Parameters for training a language model using the autotrain library.
Task specific parameters
The length parameters used for different trainers can be different. Some require more context than others.
- block_size: This is the maximum sequence length or length of one block of text. Setting to -1 determines block size automatically. Default is -1.
- model_max_length: Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage. Default is 1024
- max_prompt_length: Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input. Used only for
orpoanddpotrainer. - max_completion_length: Completion length to use, for orpo: encoder-decoder models only. For dpo, it is the length of the completion text.
NOTE:
- block size cannot be greater than model_max_length!
- max_prompt_length cannot be greater than model_max_length!
- max_prompt_length cannot be greater than block_size!
- max_completion_length cannot be greater than model_max_length!
- max_completion_length cannot be greater than block_size!
NOTE: Not following these constraints will result in an error / nan losses.
Generic Trainer
--add_eos_token, --add-eos-token
Toggle whether to automatically add an End Of Sentence (EOS) token at the end of texts, which can be critical for certain
types of models like language models. Only used for `default` trainer
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024SFT Trainer
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024Reward Trainer
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024DPO Trainer
--dpo-beta DPO_BETA, --dpo-beta DPO_BETA
Beta for DPO trainer
--model-ref MODEL_REF
Reference model to use for DPO when not using PEFT
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
--max_prompt_length MAX_PROMPT_LENGTH, --max-prompt-length MAX_PROMPT_LENGTH
Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input.
Used only for `orpo` trainer.
--max_completion_length MAX_COMPLETION_LENGTH, --max-completion-length MAX_COMPLETION_LENGTH
Completion length to use, for orpo: encoder-decoder models onlyORPO Trainer
--block_size BLOCK_SIZE, --block-size BLOCK_SIZE
Specify the block size for processing sequences. This is maximum sequence length or length of one block of text. Setting to
-1 determines block size automatically. Default is -1.
--model_max_length MODEL_MAX_LENGTH, --model-max-length MODEL_MAX_LENGTH
Set the maximum length for the model to process in a single batch, which can affect both performance and memory usage.
Default is 1024
--max_prompt_length MAX_PROMPT_LENGTH, --max-prompt-length MAX_PROMPT_LENGTH
Specify the maximum length for prompts used in training, particularly relevant for tasks requiring initial contextual input.
Used only for `orpo` trainer.
--max_completion_length MAX_COMPLETION_LENGTH, --max-completion-length MAX_COMPLETION_LENGTH
Completion length to use, for orpo: encoder-decoder models only