
Commit
•
3375b86
1
Parent(s):
d5734fd
Upload 4 files
Browse files
README.md
CHANGED
|
@@ -1,3 +1,186 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## SuperCorrect: Supervising and Correcting Language Models with Error-Driven Insights
|
| 2 |
+
|
| 3 |
+
> [SuperCorrect: Supervising and Correcting Language Models with Error-Driven Insights](link)
|
| 4 |
+
> [Ling Yang\*](https://yangling0818.github.io/), [Zhaochen Yu*](https://github.com/BitCodingWalkin), [Tianjun Zhang](https://tianjunz.github.io/), [Minkai Xu](https://minkaixu.com/), [Joseph E. Gonzalez](https://people.eecs.berkeley.edu/~jegonzal/),[Bin Cui](https://cuibinpku.github.io/), [Shuicheng Yan](https://yanshuicheng.info/)
|
| 5 |
+
>
|
| 6 |
+
> Peking University, Skywork AI, UC Berkeley, Stanford University
|
| 7 |
+
|
| 8 |
+
<p align="left">
|
| 9 |
+
<a href='https://arxiv.org/abs/to be edited'>
|
| 10 |
+
<img src='https://img.shields.io/badge/Arxiv-2410.07171-A42C25?style=flat&logo=arXiv&logoColor=A42C25'></a>
|
| 11 |
+
<a href='https://huggingface.co/BitStarWalkin/SuperCorrect-7B'>
|
| 12 |
+
<img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Models-yellow'></a>
|
| 13 |
+
</p>
|
| 14 |
+
<details>
|
| 15 |
+
<summary>Click for full abstract</summary>
|
| 16 |
+
Large language models (LLMs) like GPT-4, PaLM, and LLaMA have shown significant improvements in various reasoning tasks. However, smaller models such as Llama-3-8B and DeepSeekMath-Base still struggle with complex mathematical reasoning because they fail to effectively identify and correct reasoning errors. Recent reflection-based methods aim to address these issues by enabling self-reflection and self-correction, but they still face challenges in independently detecting errors in their reasoning steps.
|
| 17 |
+
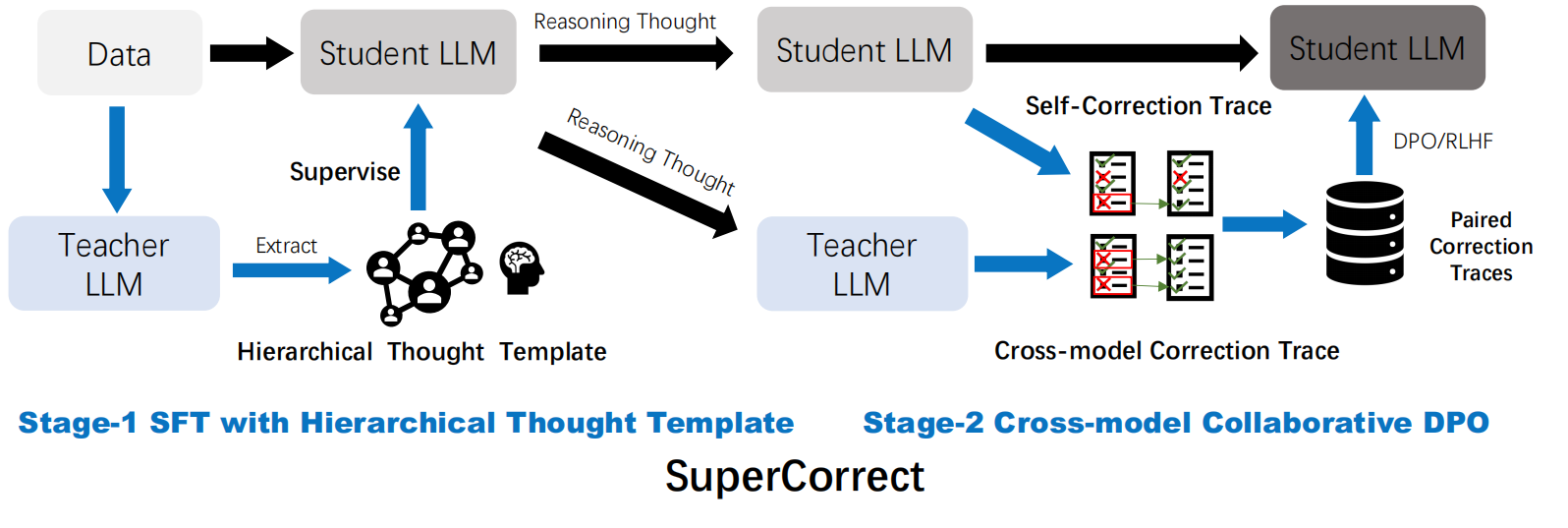
To overcome these limitations, we propose **SuperCorrect**, a novel two-stage framework that uses a large teacher model to *supervise* and *correct* both the reasoning and reflection processes of a smaller student model. In the first stage, we extract hierarchical high-level and detailed thought templates from the teacher model to guide the student model in eliciting more fine-grained reasoning thoughts. In the second stage, we introduce cross-model collaborative direct preference optimization (DPO) to enhance the self-correction abilities of the student model by following the teacher's correction traces during training. This cross-model DPO approach teaches the student model to effectively locate and resolve erroneous thoughts with error-driven insights from the teacher model, breaking the bottleneck of its thoughts and acquiring new skills and knowledge to tackle challenging problems.
|
| 18 |
+
Extensive experiments consistently demonstrate our superiority over previous methods. Notably, our **SuperCorrect-7B** model significantly **surpasses powerful DeepSeekMath-7B by 7.8%/5.3% and Qwen2.5-Math-7B by 15.1%/6.3%** on MATH/GSM8K benchmarks, achieving new SOTA performance among all 7B models.
|
| 19 |
+
</details>
|
| 20 |
+
## Introduction
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
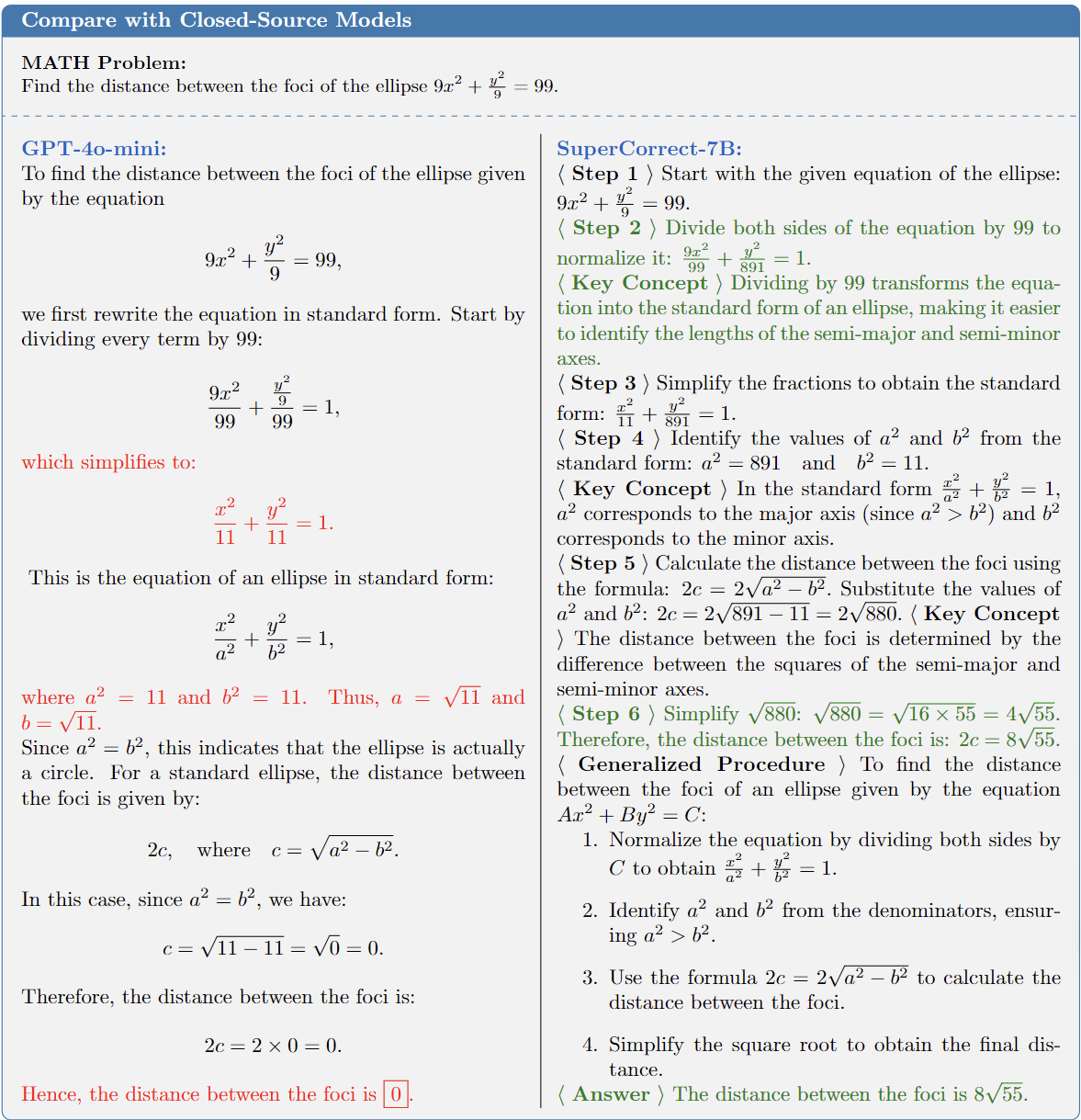
This repo provides the official implementation of **SuperCorrect** a novel two-stage fine-tuning method for improving both reasoning accuracy and self-correction ability for LLMs.
|
| 25 |
+
|
| 26 |
+
Notably, our **SupperCorrect-7B** model significantly surpasses powerful **DeepSeekMath-7B by 7.8%/5.3% and Qwen2.5-Math-7B by 15.1%/6.3% on MATH/GSM8K benchmarks**, achieving new SOTA performance among all 7B models.
|
| 27 |
+
|
| 28 |
+
Detailed performance and introduction are shown in our <a href="https://arxiv.org/"> 📑 Paper</a>.
|
| 29 |
+
|
| 30 |
+
<div align="left">
|
| 31 |
+
<b>
|
| 32 |
+
🚨 Unlike other LLMs, we incorporate LLMs with our pre-defined hierarchical thought template to conduct more deliberate reasoning than conventional CoT. It should be noted that our evaluation methods relies on pure mathematical reasoning abilities of LLMs, instead of leverage other programming methods such as PoT and ToRA.
|
| 33 |
+
</b>
|
| 34 |
+
</div>
|
| 35 |
+
## Examples
|
| 36 |
+
|
| 37 |
+

|
| 38 |
+
|
| 39 |
+
<div align="left">
|
| 40 |
+
<b>
|
| 41 |
+
🚨 For more concise and clear presentation, we omit some XML tags
|
| 42 |
+
</b>
|
| 43 |
+
</div>
|
| 44 |
+
|
| 45 |
+
## Quick Start
|
| 46 |
+
|
| 47 |
+
### Installation
|
| 48 |
+
|
| 49 |
+
```bash
|
| 50 |
+
git clone https://github.com/YangLing0818/SuperCorrect
|
| 51 |
+
cd SuperCorrect
|
| 52 |
+
conda create -n SuperCorrect python==3.10
|
| 53 |
+
conda activate SuperCorrect
|
| 54 |
+
pip install -r requirements.txt
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
### Requirements
|
| 58 |
+
|
| 59 |
+
* Since our current model is based on Qwen2.5-Math series, `transformers>=4.37.0` is needed for Qwen2.5-Math models. The latest version is recommended.
|
| 60 |
+
|
| 61 |
+
> [!Warning]
|
| 62 |
+
>
|
| 63 |
+
> <div align="center">
|
| 64 |
+
> <b>
|
| 65 |
+
> 🚨 This is a must because `transformers` integrated Qwen2 codes since `4.37.0`.
|
| 66 |
+
> </b>
|
| 67 |
+
> </div>
|
| 68 |
+
|
| 69 |
+
### Inference
|
| 70 |
+
|
| 71 |
+
#### 🤗 Hugging Face Transformers
|
| 72 |
+
|
| 73 |
+
```python
|
| 74 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 75 |
+
|
| 76 |
+
model_name = "path/to/model"
|
| 77 |
+
device = "cuda"
|
| 78 |
+
|
| 79 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 80 |
+
model_name,
|
| 81 |
+
torch_dtype="auto",
|
| 82 |
+
device_map="auto"
|
| 83 |
+
)
|
| 84 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 85 |
+
|
| 86 |
+
prompt = "Find the distance between the foci of the ellipse \[9x^2 + \frac{y^2}{9} = 99.\]"
|
| 87 |
+
hierarchical_prompt = "Solve the following math problem in a step-by-step XML format, each step should be enclosed within tags like <Step1></Step1>. For each step enclosed within the tags, determine if this step is challenging and tricky, if so, add detailed explanation and analysis enclosed within <Key> </Key> in this step, as helpful annotations to help you thinking and remind yourself how to conduct reasoning correctly. After all the reasoning steps, summarize the common solution and reasoning steps to help you and your classmates who are not good at math generalize to similar problems within <Generalized></Generalized>. Finally present the final answer within <Answer> </Answer>."
|
| 88 |
+
# HT
|
| 89 |
+
messages = [
|
| 90 |
+
{"role": "system", "content":hierarchical_prompt },
|
| 91 |
+
{"role": "user", "content": prompt}
|
| 92 |
+
]
|
| 93 |
+
|
| 94 |
+
text = tokenizer.apply_chat_template(
|
| 95 |
+
messages,
|
| 96 |
+
tokenize=False,
|
| 97 |
+
add_generation_prompt=True
|
| 98 |
+
)
|
| 99 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(device)
|
| 100 |
+
|
| 101 |
+
generated_ids = model.generate(
|
| 102 |
+
**model_inputs,
|
| 103 |
+
max_new_tokens=1024
|
| 104 |
+
)
|
| 105 |
+
generated_ids = [
|
| 106 |
+
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 110 |
+
print(response)
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
#### 🔥 vLLM
|
| 116 |
+
|
| 117 |
+
```python
|
| 118 |
+
import os
|
| 119 |
+
from vllm import LLM, SamplingParams
|
| 120 |
+
model_name = 'path/to/model'
|
| 121 |
+
hierarchical_prompt = "Solve the following math problem in a step-by-step XML format, each step should be enclosed within tags like <Step1></Step1>. For each step enclosed within the tags, determine if this step is challenging and tricky, if so, add detailed explanation and analysis enclosed within <Key> </Key> in this step, as helpful annotations to help you thinking and remind yourself how to conduct reasoning correctly. After all the reasoning steps, summarize the common solution and reasoning steps to help you and your classmates who are not good at math generalize to similar problems within <Generalized></Generalized>. Finally present the final answer within <Answer> </Answer>."
|
| 122 |
+
prompts = [
|
| 123 |
+
"For what positive value of $t$ is $|{-4+ti}| = 6$?",
|
| 124 |
+
"Find the distance between the foci of the ellipse \\[9x^2 + \\frac{y^2}{9} = 99.\\]",
|
| 125 |
+
"The fourth term of a geometric series is $24$ and the eleventh term is $3072$. What is the common ratio?"
|
| 126 |
+
]
|
| 127 |
+
combined_prompts = [hierarchial_prompt + '\n' + prompt for prompt in prompts]
|
| 128 |
+
sampling_params = SamplingParams(temperature=0, top_p=1,max_tokens=1024)
|
| 129 |
+
llm = LLM(model=model_name, trust_remote_code=True)
|
| 130 |
+
outputs = llm.generate(combined_prompts, sampling_params)
|
| 131 |
+
|
| 132 |
+
#Print the outputs.
|
| 133 |
+
for output in outputs:
|
| 134 |
+
prompt = output.prompt
|
| 135 |
+
generated_text = output.outputs[0].text
|
| 136 |
+
print(f"Prompt: {prompt}")
|
| 137 |
+
print(f"Generated text: {generated_text}")
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
Here we also provide inference code with [vLLM](https://github.com/vllm-project/vllm) . vLLM is a fast and easy-to-use library for LLM inference and serving.
|
| 141 |
+
|
| 142 |
+
## Performance
|
| 143 |
+
|
| 144 |
+
We evaluate our SupperCorrect-7B on two widely used English math benchmarks GSM8K and MATH. All evaluations are tested with our evaluation method which is zero-shot hierarchical thought based prompting.
|
| 145 |
+
|
| 146 |
+

|
| 147 |
+
|
| 148 |
+
## Evaluation
|
| 149 |
+
|
| 150 |
+
Since we use hierarchical thought based reasoning data in the fine-tuning stage, other evaluation methods may not reproduce the best results shown in our paper.
|
| 151 |
+
|
| 152 |
+
Here we provide two different evaluation methods including **LLM-based version** which utilizes LLMs to conduct a more fair and robust judgement and **minerva version** which utilize programming method to verify the final results. Both methods aims to provide a more accurate and strict evaluation results, as the final results in MATH dataset are not always numeric or pure expression. **We now only support LLM-based version for evaluation, we will update soon for off-line evaluation.**
|
| 153 |
+
|
| 154 |
+
Feel free to reproduce the results of our SuperCorrect with scripts in [evaluation](./evaluation). And our SuperCorrect is consistent in different prompting methods, feel free to test our model on [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) and [Qwen2.5-Math](https://github.com/QwenLM/Qwen2.5-Math) with their default settings.
|
| 155 |
+
|
| 156 |
+
### Evaluation Code
|
| 157 |
+
|
| 158 |
+
Evaluate SuperCorrect-7B model with the following command:
|
| 159 |
+
|
| 160 |
+
```bash
|
| 161 |
+
API_KEY= "Input your key here"
|
| 162 |
+
MODEL_NAME_OR_PATH="BitStarWalkin/SuperCorrect-7B"
|
| 163 |
+
export CUDA_VISIBLE_DEVICES="0"
|
| 164 |
+
bash evaluation.sh $API_KEY $MODEL_NAME_OR_PATH
|
| 165 |
+
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
## Citation
|
| 169 |
+
|
| 170 |
+
```bash
|
| 171 |
+
@article{yang2024super,
|
| 172 |
+
title={SuperCorrect: Supervising and Correcting Language Models with Error-Driven Insights}
|
| 173 |
+
SuperCorrect
|
| 174 |
+
}
|
| 175 |
+
@article{yang2024buffer,
|
| 176 |
+
title={Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models},
|
| 177 |
+
author={Yang, Ling and Yu, Zhaochen and Zhang, Tianjun and Cao, Shiyi and Xu, Minkai and Zhang, Wentao and Gonzalez, Joseph E and Cui, Bin},
|
| 178 |
+
journal={arXiv preprint arXiv:2406.04271},
|
| 179 |
+
year={2024}
|
| 180 |
+
}
|
| 181 |
+
```
|
| 182 |
+
|
| 183 |
+
## Acknowledgements
|
| 184 |
+
|
| 185 |
+
Our SuperCorrect is a two-stage fine-tuning model which based on several extraordinary open-source models like [Qwen2.5-Math](https://github.com/QwenLM/Qwen2.5-Math), [DeepSeek-Math](https://github.com/deepseek-ai/DeepSeek-Math), [Llama3-Series](https://github.com/meta-llama/llama3). Our evaluation method is based on the code base of outstanding works like [Qwen2.5-Math](https://github.com/QwenLM/Qwen2.5-Math) and [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness). We also want to express our gratitude for amazing works such as [BoT](https://github.com/YangLing0818/buffer-of-thought-llm) which provides the idea of thought template.
|
| 186 |
+
|
example1.png
ADDED
|
intro.png
ADDED
|
table.png
ADDED

|