模型是数据集BAAI/IndustryCorpus2中用来进行行业分类分类
模型细节:
为了提升数据集中行业划分对实际行业的覆盖,并对齐国家标准中定义的行业目录,我们参考国家统计局制定的国民经济行业分类体系和世界知识体系,进行类目的合并和整合,设计了覆盖中英文的最终的31个行业类目。类目表名称如下所示
{
"数学_统计": {"zh": "数学与统计", "en": "Math & Statistics"},
"体育": {"zh": "体育", "en": "Sports"},
"农林牧渔": {"zh": "农业与渔业", "en": "Agriculture & Fisheries"},
"房地产_建筑": {"zh": "房地产与建筑", "en": "Real Estate & Construction"},
"时政_政务_行政": {"zh": "政治与行政", "en": "Politics & Administration"},
"消防安全_食品安全": {"zh": "安全管理", "en": "Safety Management"},
"石油化工": {"zh": "石油化工", "en": "Petrochemicals"},
"计算机_通信": {"zh": "计算机与通信", "en": "Computing & Telecommunications"},
"交通运输": {"zh": "交通运输", "en": "Transportation"},
"其他": {"zh": "其他", "en": "Others"},
"医学_健康_心理_中医": {"zh": "健康与医学", "en": "Health & Medicine"},
"文学_情感": {"zh": "文学与情感", "en": "Literature & Emotions"},
"水利_海洋": {"zh": "水利与海洋", "en": "Water Resources & Marine"},
"游戏": {"zh": "游戏", "en": "Gaming"},
"科技_科学研究": {"zh": "科技与研究", "en": "Technology & Research"},
"采矿": {"zh": "采矿", "en": "Mining"},
"人工智能_机器学习": {"zh": "人工智能", "en": "Artificial Intelligence"},
"其他信息服务_信息安全": {"zh": "信息服务", "en": "Information Services"},
"学科教育_教育": {"zh": "学科教育", "en": "Subject Education"},
"新闻传媒": {"zh": "新闻传媒", "en": "Media & Journalism"},
"汽车": {"zh": "汽车", "en": "Automobiles"},
"生物医药": {"zh": "生物医药", "en": "Biopharmaceuticals"},
"航空航天": {"zh": "航空航天", "en": "Aerospace"},
"金融_经济": {"zh": "金融与经济", "en": "Finance & Economics"},
"住宿_餐饮_酒店": {"zh": "住宿与餐饮", "en": "Hospitality & Catering"},
"其他制造": {"zh": "制造业", "en": "Manufacturing"},
"影视_娱乐": {"zh": "影视与娱乐", "en": "Film & Entertainment"},
"旅游_地理": {"zh": "旅游与地理", "en": "Travel & Geography"},
"法律_司法": {"zh": "法律与司法", "en": "Law & Justice"},
"电力能源": {"zh": "电力与能源", "en": "Power & Energy"},
"计算机编程_代码": {"zh": "编程", "en": "Programming"},
}
行业分类模型的数据构造
数据构建
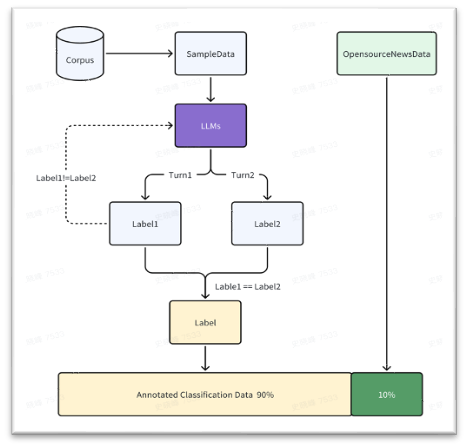
数据来源:预训练预训练语料抽样和开源文本分类数据,其中预训练语料占比90%,通过数据采样,保证中英文数据占比为1:1
标签构造:使用LLM模型对数据进行多次分类判定,筛选多次判定一致的数据作为训练数据
数据规模:36K
数据构造的整体流程如下:
模型训练:
参数更新:在预训练的bert模型上添加分类头进行文本分类模型训练
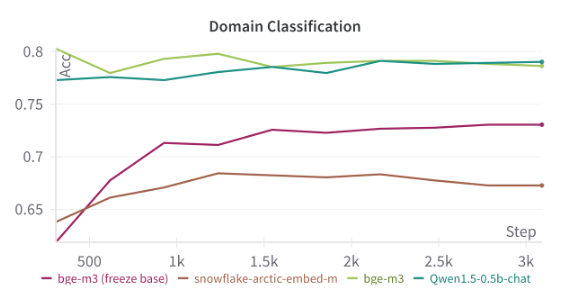
模型选型:考虑的模型性能和推理效率,我们选用了0.5b规模的模型,通过对比实验最终最终选择了bge-m3并全参数训练的方式,作为我们的基座模型
训练超参:全参数训练,max_length = 2048,lr=1e-5,batch_size=64,,验证集评估acc:86%